3 Linear Regression
3.1 Conceptual
3.1.1 Question 1
Describe the null hypotheses to which the p-values given in Table 3.4 correspond. Explain what conclusions you can draw based on these p-values. Your explanation should be phrased in terms of
sales,TV,radio, andnewspaper, rather than in terms of the coefficients of the linear model.
For intercept, that \(\beta_0 = 0\) For the others, that \(\beta_n = 0\) (for \(n = 1, 2, 3\))
We can conclude that without any spending, there are still some sales (the intercept is not 0). Furthermore, we can conclude that money spent on TV and radio are significantly associated with increased sales, but the same cannot be said of newspaper spending.
3.1.2 Question 2
Carefully explain the differences between the KNN classifier and KNN regression methods.
The KNN classifier is categorical and assigns a value based on the most frequent observed category among \(K\) nearest neighbors, whereas KNN regression assigns a continuous variable, the average of the response variables for the \(K\) nearest neighbors.
3.1.3 Question 3
Suppose we have a data set with five predictors, \(X_1\) = GPA, \(X_2\) = IQ, \(X_3\) = Level (1 for College and 0 for High School), \(X_4\) = Interaction between GPA and IQ, and \(X_5\) = Interaction between GPA and Level. The response is starting salary after graduation (in thousands of dollars). Suppose we use least squares to fit the model, and get \(\hat\beta_0 = 50\), \(\hat\beta_1 = 20\), \(\hat\beta_2 = 0.07\), \(\hat\beta_3 = 35\), \(\hat\beta_4 = 0.01\), \(\hat\beta_5 = -10\).
- Which answer is correct, and why?
- For a fixed value of IQ and GPA, high school graduates earn more on average than college graduates.
- For a fixed value of IQ and GPA, college graduates earn more on average than high school graduates.
- For a fixed value of IQ and GPA, high school graduates earn more on average than college graduates provided that the GPA is high enough.
- For a fixed value of IQ and GPA, college graduates earn more on average than high school graduates provided that the GPA is high enough.
The model is:
\(y = \beta_0 + \beta_1 \cdot \text{GPA} + \beta_2 \cdot \text{IQ} + \beta_3 \cdot \text{Level} + \beta_4 \cdot \text{GPA} \cdot \text{IQ} + \beta_5 \cdot \text{GPA} \cdot \text{Level}\)
Fixing IQ and GPA, changing Level from 0 to 1 will change the outcome by:
\(\Delta y = \beta_3 + \beta_5 \cdot \text{GPA}\)
\(\Delta y > 0 \Rightarrow \beta_3 + \beta_5 \cdot \text{GPA} > 0 \Rightarrow \text{GPA} < \dfrac{-\beta_3}{\beta_5} = \dfrac{-35}{-10} = 3.5\)
From a graphical standpoint:
model <- function(gpa, iq, level) {
50 +
gpa * 20 +
iq * 0.07 +
level * 35 +
gpa * iq * 0.01 +
gpa * level * -10
}
x <- seq(1, 5, length = 10)
y <- seq(1, 200, length = 20)
college <- t(outer(x, y, model, level = 1))
high_school <- t(outer(x, y, model, level = 0))
plot_ly(x = x, y = y) |>
add_surface(
z = ~college,
colorscale = list(c(0, 1), c("rgb(107,184,214)", "rgb(0,90,124)")),
colorbar = list(title = "College")
) |>
add_surface(
z = ~high_school,
colorscale = list(c(0, 1), c("rgb(255,112,184)", "rgb(128,0,64)")),
colorbar = list(title = "High school")
) |>
layout(scene = list(
xaxis = list(title = "GPA"),
yaxis = list(title = "IQ"),
zaxis = list(title = "Salary")
))Option iii correct.
- Predict the salary of a college graduate with IQ of 110 and a GPA of 4.0.
## [1] 137.1
- True or false: Since the coefficient for the GPA/IQ interaction term is very small, there is very little evidence of an interaction effect. Justify your answer.
This is false. It is important to remember that GPA and IQ vary over different scales. It is better to explicitly test the significance of the interaction effect, and/or visualize or quantify the effect on salary under realistic ranges of GPA/IQ values.
3.1.4 Question 4
I collect a set of data (\(n = 100\) observations) containing a single predictor and a quantitative response. I then fit a linear regression model to the data, as well as a separate cubic regression, i.e. \(Y = \beta_0 + \beta_1X + \beta_2X^2 + \beta_3X^3 + \epsilon\).
- Suppose that the true relationship between \(X\) and \(Y\) is linear, i.e. \(Y = \beta_0 + \beta_1X + \epsilon\). Consider the training residual sum of squares (RSS) for the linear regression, and also the training RSS for the cubic regression. Would we expect one to be lower than the other, would we expect them to be the same, or is there not enough information to tell? Justify your answer.
You would expect the cubic regression to have lower RSS since it is at least as flexible as the linear regression.
- Answer (a) using test rather than training RSS.
Though we could not be certain, the test RSS would likely be higher due to overfitting.
- Suppose that the true relationship between \(X\) and \(Y\) is not linear, but we don’t know how far it is from linear. Consider the training RSS for the linear regression, and also the training RSS for the cubic regression. Would we expect one to be lower than the other, would we expect them to be the same, or is there not enough information to tell? Justify your answer.
You would expect the cubic regression to have lower RSS since it is at least as flexible as the linear regression.
- Answer (c) using test rather than training RSS.
There is not enough information to tell, it depends on how non-linear the true relationship is.
3.1.5 Question 5
Consider the fitted values that result from performing linear regression without an intercept. In this setting, the ith fitted value takes the form \[\hat{y}_i = x_i\hat\beta,\] where \[\hat{\beta} = \left(\sum_{i=1}^nx_iy_i\right) / \left(\sum_{i' = 1}^n x^2_{i'}\right).\] show that we can write \[\hat{y}_i = \sum_{i' = 1}^na_{i'}y_{i'}\] What is \(a_{i'}\)?
Note: We interpret this result by saying that the fitted values from linear regression are linear combinations of the response values.
\[\begin{align} \hat{y}_i & = x_i \frac{\sum_{i=1}^nx_iy_i}{\sum_{i' = 1}^n x^2_{i'}} \\ & = x_i \frac{\sum_{i'=1}^nx_{i'}y_{i'}}{\sum_{i'' = 1}^n x^2_{i''}} \\ & = \frac{\sum_{i'=1}^n x_i x_{i'}y_{i'}}{\sum_{i'' = 1}^n x^2_{i''}} \\ & = \sum_{i'=1}^n \frac{ x_i x_{i'}y_{i'}}{\sum_{i'' = 1}^n x^2_{i''}} \\ & = \sum_{i'=1}^n \frac{ x_i x_{i'}}{\sum_{i'' = 1}^n x^2_{i''}} y_{i'} \end{align}\]
therefore,
\[a_{i'} = \frac{ x_i x_{i'}}{\sum x^2}\]
3.1.6 Question 6
Using (3.4), argue that in the case of simple linear regression, the least squares line always passes through the point \((\bar{x}, \bar{y})\).
when \(x = \bar{x}\) what is \(y\)?
\[\begin{align} y &= \hat\beta_0 + \hat\beta_1\bar{x} \\ &= \bar{y} - \hat\beta_1\bar{x} + \hat\beta_1\bar{x} \\ &= \bar{y} \end{align}\]
3.1.7 Question 7
It is claimed in the text that in the case of simple linear regression of \(Y\) onto \(X\), the \(R^2\) statistic (3.17) is equal to the square of the correlation between \(X\) and \(Y\) (3.18). Prove that this is the case. For simplicity, you may assume that \(\bar{x} = \bar{y} = 0\).
We have the following equations:
\[ R^2 = \frac{\textit{TSS} - \textit{RSS}}{\textit{TSS}} \] \[ Cor(x,y) = \frac{\sum_i (x_i-\bar{x})(y_i - \bar{y})}{\sqrt{\sum_i(x_i - \bar{x})^2}\sqrt{\sum_i(y_i - \bar{y})^2}} \]
As above, its important to remember \(\sum_i x_i = \sum_j x_j\)
when \(\bar{x} = \bar{y} = 0\) \[ Cor(x,y)^2 = \frac{(\sum_ix_iy_i)^2}{\sum_ix_i^2 \sum_iy_i^2} \]
Also note that:
\[\hat{y}_i = \hat\beta_0 + \hat\beta_1x_i = x_i\frac{\sum_j{x_jy_j}}{\sum_jx_j^2}\]
Therefore, given that \(RSS = \sum_i(y_i - \hat{y}_i)^2\) and \(\textit{TSS} = \sum_i(y_i - \bar{y})^2 = \sum_iy_i^2\)
\[\begin{align} R^2 &= \frac{\sum_iy_i^2 - \sum_i(y_i - x_i\frac{\sum_j{x_jy_j}}{\sum_jx_j^2})^2} {\sum_iy_i^2} \\ &= \frac{\sum_iy_i^2 - \sum_i( y_i^2 - 2y_ix_i\frac{\sum_j{x_jy_j}}{\sum_jx_j^2} + x_i^2 (\frac{\sum_j{x_jy_j}}{\sum_jx_j^2})^2 )}{\sum_iy_i^2} \\ &= \frac{ 2\sum_i(y_ix_i\frac{\sum_j{x_jy_j}}{\sum_jx_j^2}) - \sum_i(x_i^2 (\frac{\sum_j{x_jy_j}}{\sum_jx_j^2})^2) }{\sum_iy_i^2} \\ &= \frac{ 2\sum_i(y_ix_i) \frac{\sum_j{x_jy_j}}{\sum_jx_j^2} - \sum_i(x_i^2) \frac{(\sum_j{x_jy_j})^2}{(\sum_jx_j^2)^2} }{\sum_iy_i^2} \\ &= \frac{ 2\frac{(\sum_i{x_iy_i})^2}{\sum_jx_j^2} - \frac{(\sum_i{x_iy_i})^2}{\sum_jx_j^2} }{\sum_iy_i^2} \\ &= \frac{(\sum_i{x_iy_i})^2}{\sum_ix_i^2 \sum_iy_i^2} \end{align}\]
3.2 Applied
3.2.1 Question 8
This question involves the use of simple linear regression on the Auto data set.
- Use the
lm()function to perform a simple linear regression withmpgas the response andhorsepoweras the predictor. Use thesummary()function to print the results. Comment on the output. For example:- Is there a relationship between the predictor and the response?
- How strong is the relationship between the predictor and the response?
- Is the relationship between the predictor and the response positive or negative?
- What is the predicted mpg associated with a horsepower of 98?
- What are the associated 95% confidence and prediction intervals?
##
## Call:
## lm(formula = mpg ~ horsepower, data = Auto)
##
## Residuals:
## Min 1Q Median 3Q Max
## -13.5710 -3.2592 -0.3435 2.7630 16.9240
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 39.935861 0.717499 55.66 <2e-16 ***
## horsepower -0.157845 0.006446 -24.49 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 4.906 on 390 degrees of freedom
## Multiple R-squared: 0.6059, Adjusted R-squared: 0.6049
## F-statistic: 599.7 on 1 and 390 DF, p-value: < 2.2e-16Yes, there is a significant relationship between predictor and response. For every unit increase in horsepower, mpg reduces by 0.16 (a negative relationship).
## fit lwr upr
## 1 24.46708 23.97308 24.96108## fit lwr upr
## 1 24.46708 14.8094 34.12476
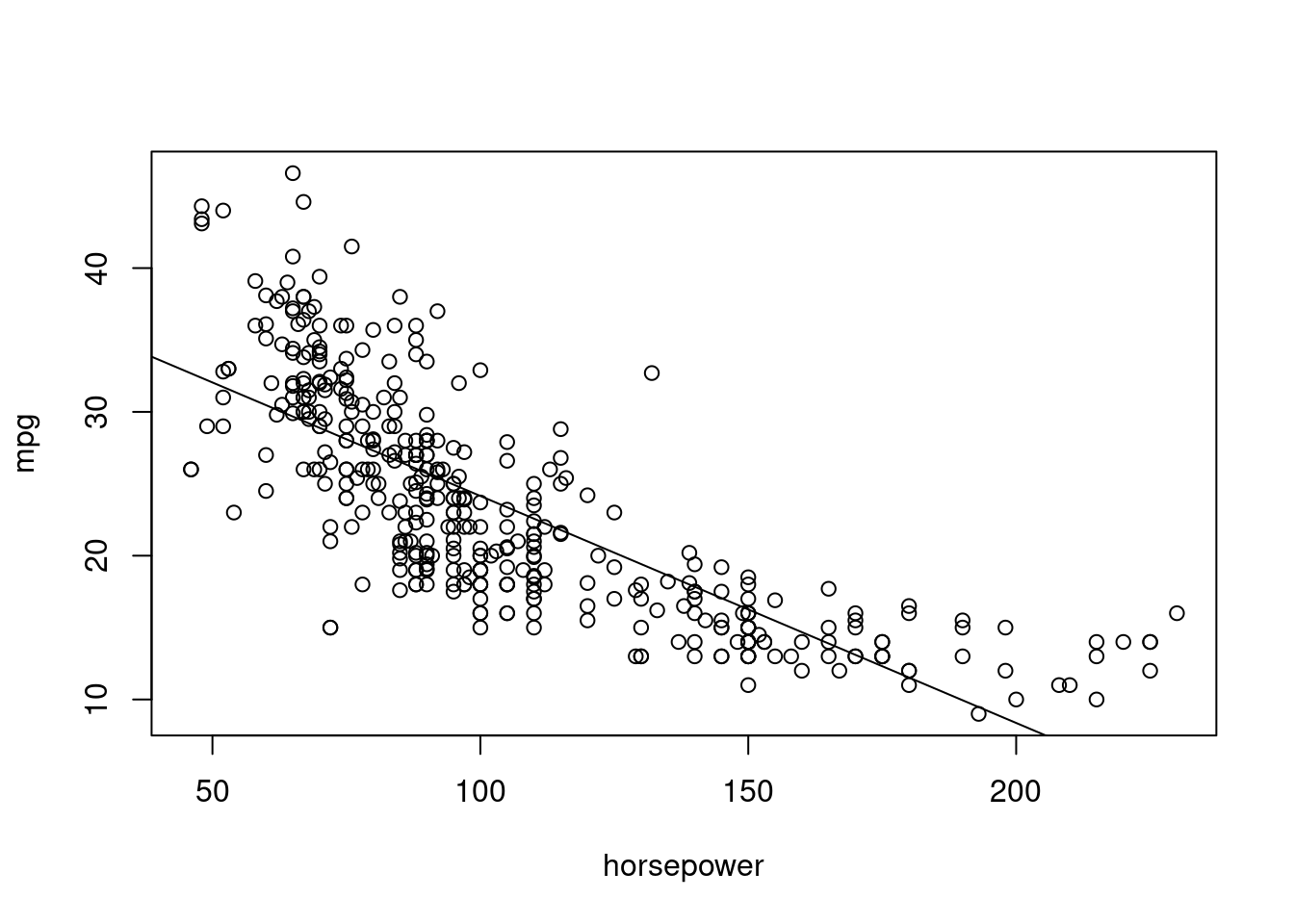
- Plot the response and the predictor. Use the
abline()function to display the least squares regression line.
- Use the
plot()function to produce diagnostic plots of the least squares regression fit. Comment on any problems you see with the fit.
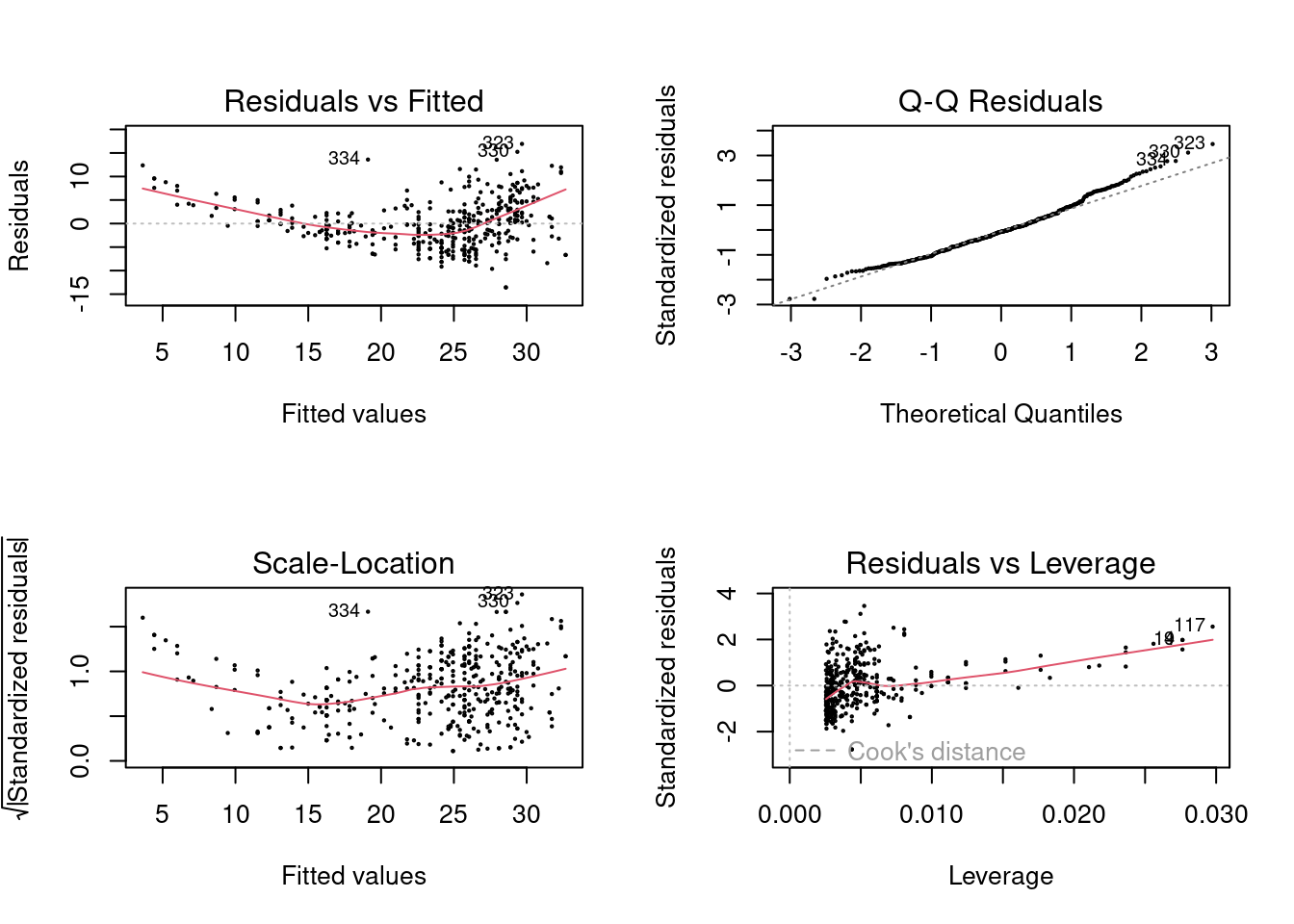
The residuals show a trend with respect to the fitted values suggesting a non-linear relationship.
3.2.2 Question 9
This question involves the use of multiple linear regression on the
Autodata set.
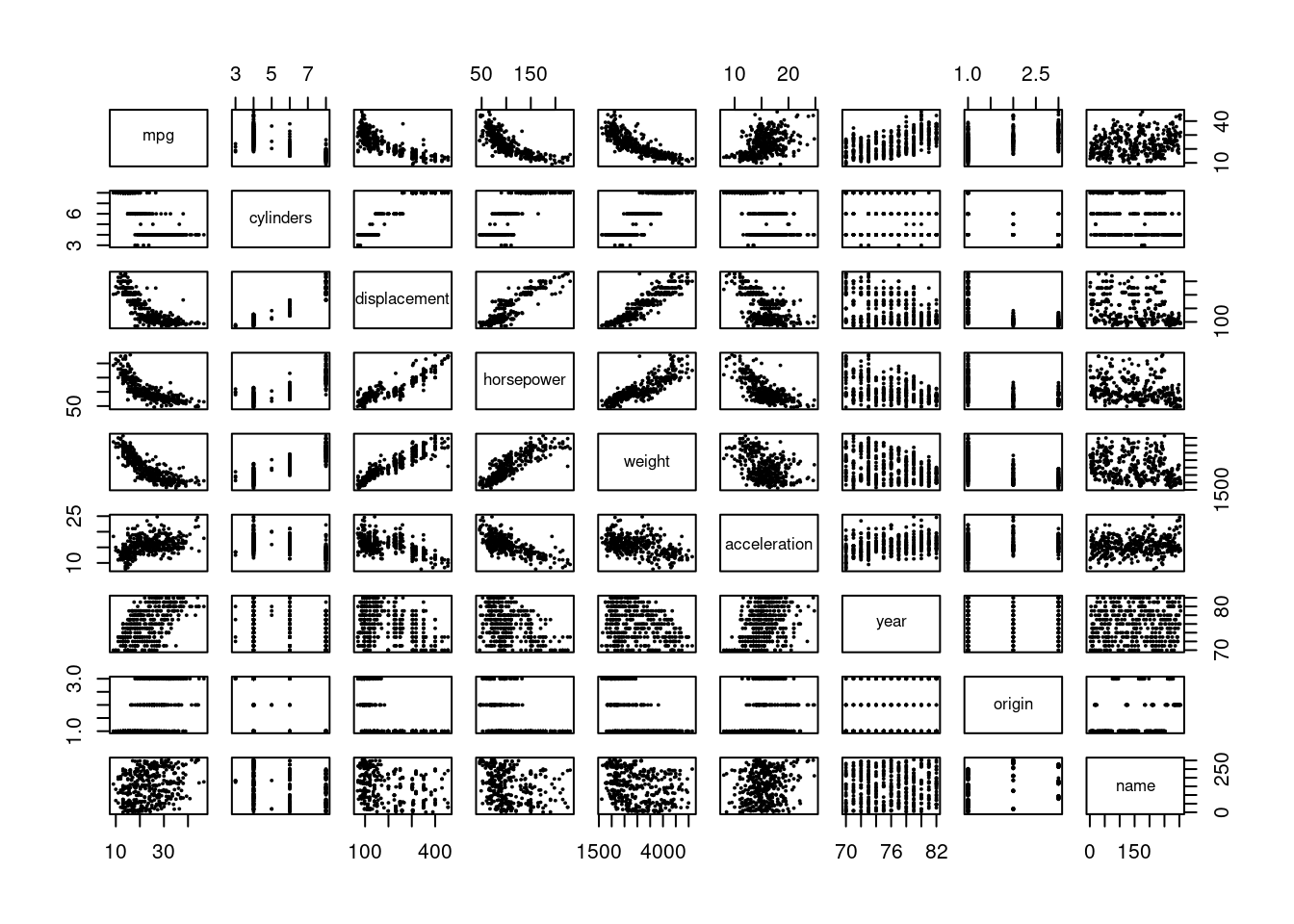
- Produce a scatterplot matrix which includes all of the variables in the data set.
- Compute the matrix of correlations between the variables using the function
cor(). You will need to exclude the name variable,namewhich is qualitative.
## mpg cylinders displacement horsepower weight
## mpg 1.0000000 -0.7776175 -0.8051269 -0.7784268 -0.8322442
## cylinders -0.7776175 1.0000000 0.9508233 0.8429834 0.8975273
## displacement -0.8051269 0.9508233 1.0000000 0.8972570 0.9329944
## horsepower -0.7784268 0.8429834 0.8972570 1.0000000 0.8645377
## weight -0.8322442 0.8975273 0.9329944 0.8645377 1.0000000
## acceleration 0.4233285 -0.5046834 -0.5438005 -0.6891955 -0.4168392
## year 0.5805410 -0.3456474 -0.3698552 -0.4163615 -0.3091199
## origin 0.5652088 -0.5689316 -0.6145351 -0.4551715 -0.5850054
## acceleration year origin
## mpg 0.4233285 0.5805410 0.5652088
## cylinders -0.5046834 -0.3456474 -0.5689316
## displacement -0.5438005 -0.3698552 -0.6145351
## horsepower -0.6891955 -0.4163615 -0.4551715
## weight -0.4168392 -0.3091199 -0.5850054
## acceleration 1.0000000 0.2903161 0.2127458
## year 0.2903161 1.0000000 0.1815277
## origin 0.2127458 0.1815277 1.0000000
- Use the
lm()function to perform a multiple linear regression withmpgas the response and all other variables except name as the predictors. Use thesummary()function to print the results. Comment on the output. For instance:
- Is there a relationship between the predictors and the response?
- Which predictors appear to have a statistically significant relationship to the response?
- What does the coefficient for the
yearvariable suggest?
##
## Call:
## lm(formula = mpg ~ ., data = x)
##
## Residuals:
## Min 1Q Median 3Q Max
## -9.5903 -2.1565 -0.1169 1.8690 13.0604
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -17.218435 4.644294 -3.707 0.00024 ***
## cylinders -0.493376 0.323282 -1.526 0.12780
## displacement 0.019896 0.007515 2.647 0.00844 **
## horsepower -0.016951 0.013787 -1.230 0.21963
## weight -0.006474 0.000652 -9.929 < 2e-16 ***
## acceleration 0.080576 0.098845 0.815 0.41548
## year 0.750773 0.050973 14.729 < 2e-16 ***
## origin 1.426141 0.278136 5.127 4.67e-07 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 3.328 on 384 degrees of freedom
## Multiple R-squared: 0.8215, Adjusted R-squared: 0.8182
## F-statistic: 252.4 on 7 and 384 DF, p-value: < 2.2e-16Yes, there is a relationship between some predictors and response, notably “displacement” (positive), “weight” (negative), “year” (positive) and “origin” (positive).
The coefficient for year (which is positive \(~0.75\)) suggests that mpg increases by about this amount every year on average.
- Use the
plot()function to produce diagnostic plots of the linear regression fit. Comment on any problems you see with the fit. Do the residual plots suggest any unusually large outliers? Does the leverage plot identify any observations with unusually high leverage?
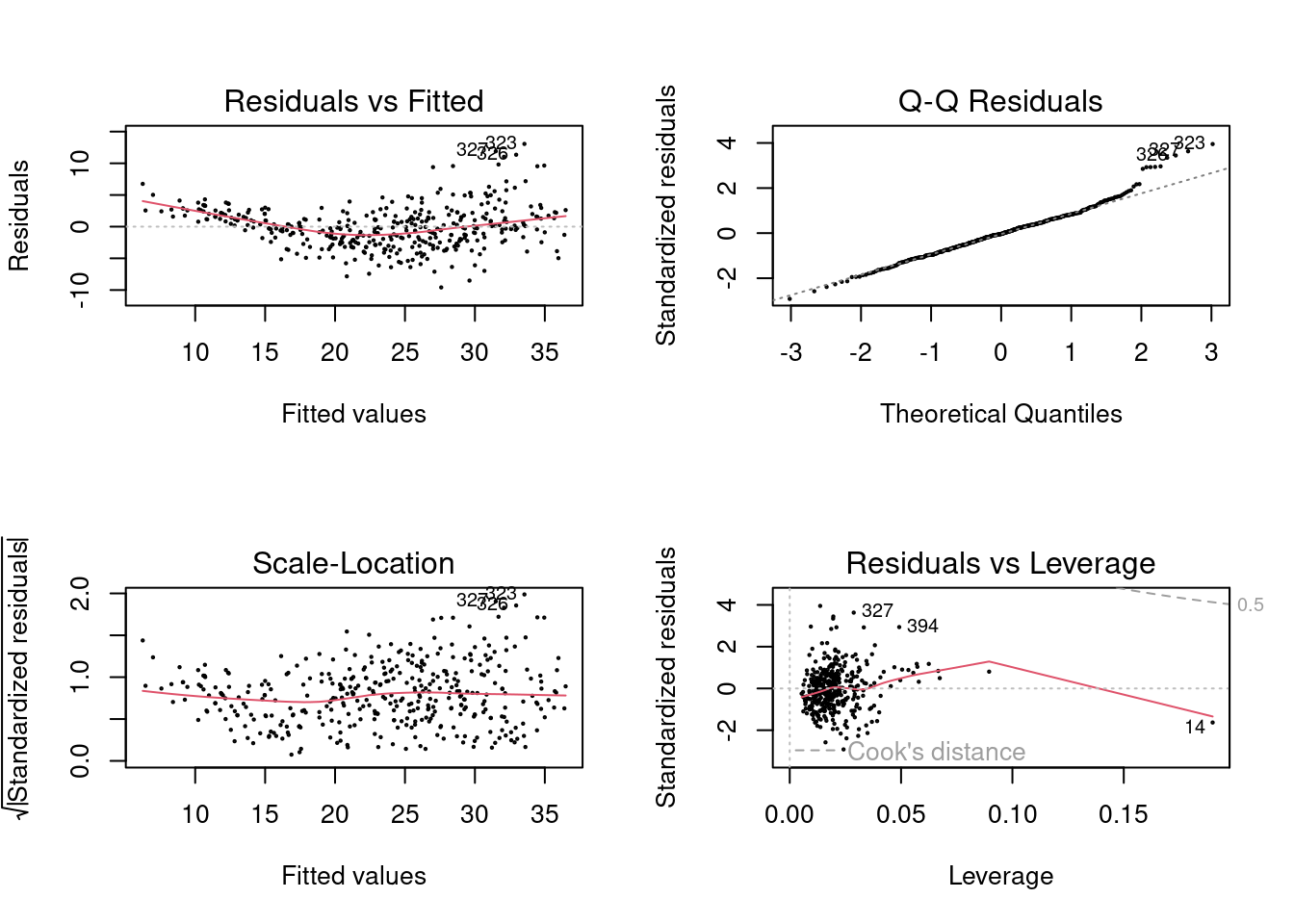
One point has high leverage, the residuals also show a trend with fitted values.
- Use the
*and:symbols to fit linear regression models with interaction effects. Do any interactions appear to be statistically significant?
##
## Call:
## lm(formula = mpg ~ . + weight:horsepower, data = x)
##
## Residuals:
## Min 1Q Median 3Q Max
## -8.589 -1.617 -0.184 1.541 12.001
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 2.876e+00 4.511e+00 0.638 0.524147
## cylinders -2.955e-02 2.881e-01 -0.103 0.918363
## displacement 5.950e-03 6.750e-03 0.881 0.378610
## horsepower -2.313e-01 2.363e-02 -9.791 < 2e-16 ***
## weight -1.121e-02 7.285e-04 -15.393 < 2e-16 ***
## acceleration -9.019e-02 8.855e-02 -1.019 0.309081
## year 7.695e-01 4.494e-02 17.124 < 2e-16 ***
## origin 8.344e-01 2.513e-01 3.320 0.000986 ***
## horsepower:weight 5.529e-05 5.227e-06 10.577 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 2.931 on 383 degrees of freedom
## Multiple R-squared: 0.8618, Adjusted R-squared: 0.859
## F-statistic: 298.6 on 8 and 383 DF, p-value: < 2.2e-16##
## Call:
## lm(formula = mpg ~ . + acceleration:horsepower, data = x)
##
## Residuals:
## Min 1Q Median 3Q Max
## -9.0329 -1.8177 -0.1183 1.7247 12.4870
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -32.499820 4.923380 -6.601 1.36e-10 ***
## cylinders 0.083489 0.316913 0.263 0.792350
## displacement -0.007649 0.008161 -0.937 0.349244
## horsepower 0.127188 0.024746 5.140 4.40e-07 ***
## weight -0.003976 0.000716 -5.552 5.27e-08 ***
## acceleration 0.983282 0.161513 6.088 2.78e-09 ***
## year 0.755919 0.048179 15.690 < 2e-16 ***
## origin 1.035733 0.268962 3.851 0.000138 ***
## horsepower:acceleration -0.012139 0.001772 -6.851 2.93e-11 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 3.145 on 383 degrees of freedom
## Multiple R-squared: 0.841, Adjusted R-squared: 0.8376
## F-statistic: 253.2 on 8 and 383 DF, p-value: < 2.2e-16##
## Call:
## lm(formula = mpg ~ . + cylinders:weight, data = x)
##
## Residuals:
## Min 1Q Median 3Q Max
## -10.9484 -1.7133 -0.1809 1.4530 12.4137
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 7.3143478 5.0076737 1.461 0.14494
## cylinders -5.0347425 0.5795767 -8.687 < 2e-16 ***
## displacement 0.0156444 0.0068409 2.287 0.02275 *
## horsepower -0.0314213 0.0126216 -2.489 0.01322 *
## weight -0.0150329 0.0011125 -13.513 < 2e-16 ***
## acceleration 0.1006438 0.0897944 1.121 0.26306
## year 0.7813453 0.0464139 16.834 < 2e-16 ***
## origin 0.8030154 0.2617333 3.068 0.00231 **
## cylinders:weight 0.0015058 0.0001657 9.088 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 3.022 on 383 degrees of freedom
## Multiple R-squared: 0.8531, Adjusted R-squared: 0.8501
## F-statistic: 278.1 on 8 and 383 DF, p-value: < 2.2e-16There are at least three cases where the interactions appear to be highly significant.
- Try a few different transformations of the variables, such as \(log(X)\), \(\sqrt{X}\), \(X^2\). Comment on your findings.
Here I’ll just consider transformations for horsepower.
par(mfrow = c(2, 2))
plot(Auto$horsepower, Auto$mpg, cex = 0.2)
plot(log(Auto$horsepower), Auto$mpg, cex = 0.2)
plot(sqrt(Auto$horsepower), Auto$mpg, cex = 0.2)
plot(Auto$horsepower^2, Auto$mpg, cex = 0.2)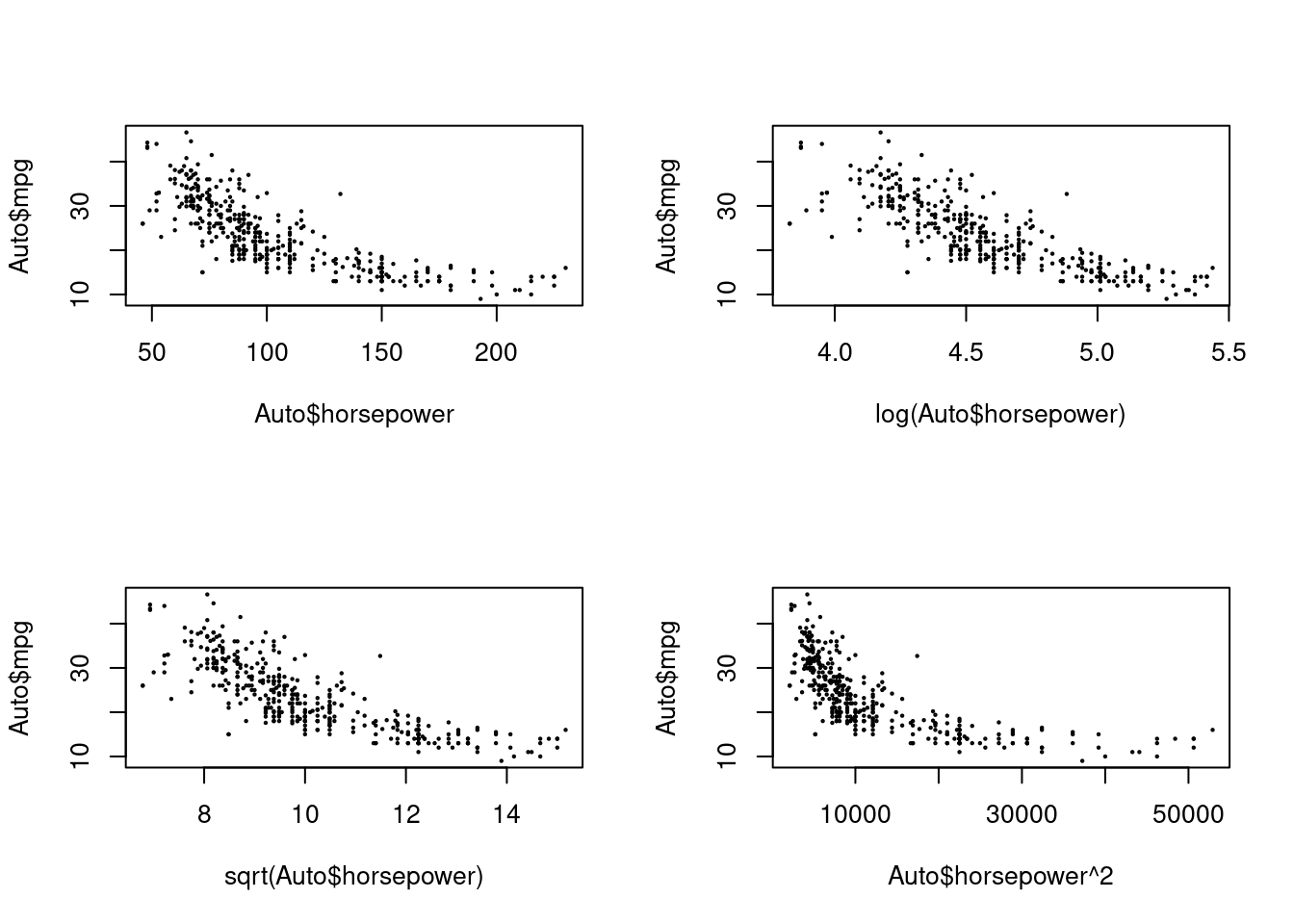
x <- subset(Auto, select = -name)
x$horsepower <- log(x$horsepower)
fit <- lm(mpg ~ ., data = x)
summary(fit)##
## Call:
## lm(formula = mpg ~ ., data = x)
##
## Residuals:
## Min 1Q Median 3Q Max
## -9.3115 -2.0041 -0.1726 1.8393 12.6579
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 27.254005 8.589614 3.173 0.00163 **
## cylinders -0.486206 0.306692 -1.585 0.11372
## displacement 0.019456 0.006876 2.830 0.00491 **
## horsepower -9.506436 1.539619 -6.175 1.69e-09 ***
## weight -0.004266 0.000694 -6.148 1.97e-09 ***
## acceleration -0.292088 0.103804 -2.814 0.00515 **
## year 0.705329 0.048456 14.556 < 2e-16 ***
## origin 1.482435 0.259347 5.716 2.19e-08 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 3.18 on 384 degrees of freedom
## Multiple R-squared: 0.837, Adjusted R-squared: 0.834
## F-statistic: 281.6 on 7 and 384 DF, p-value: < 2.2e-16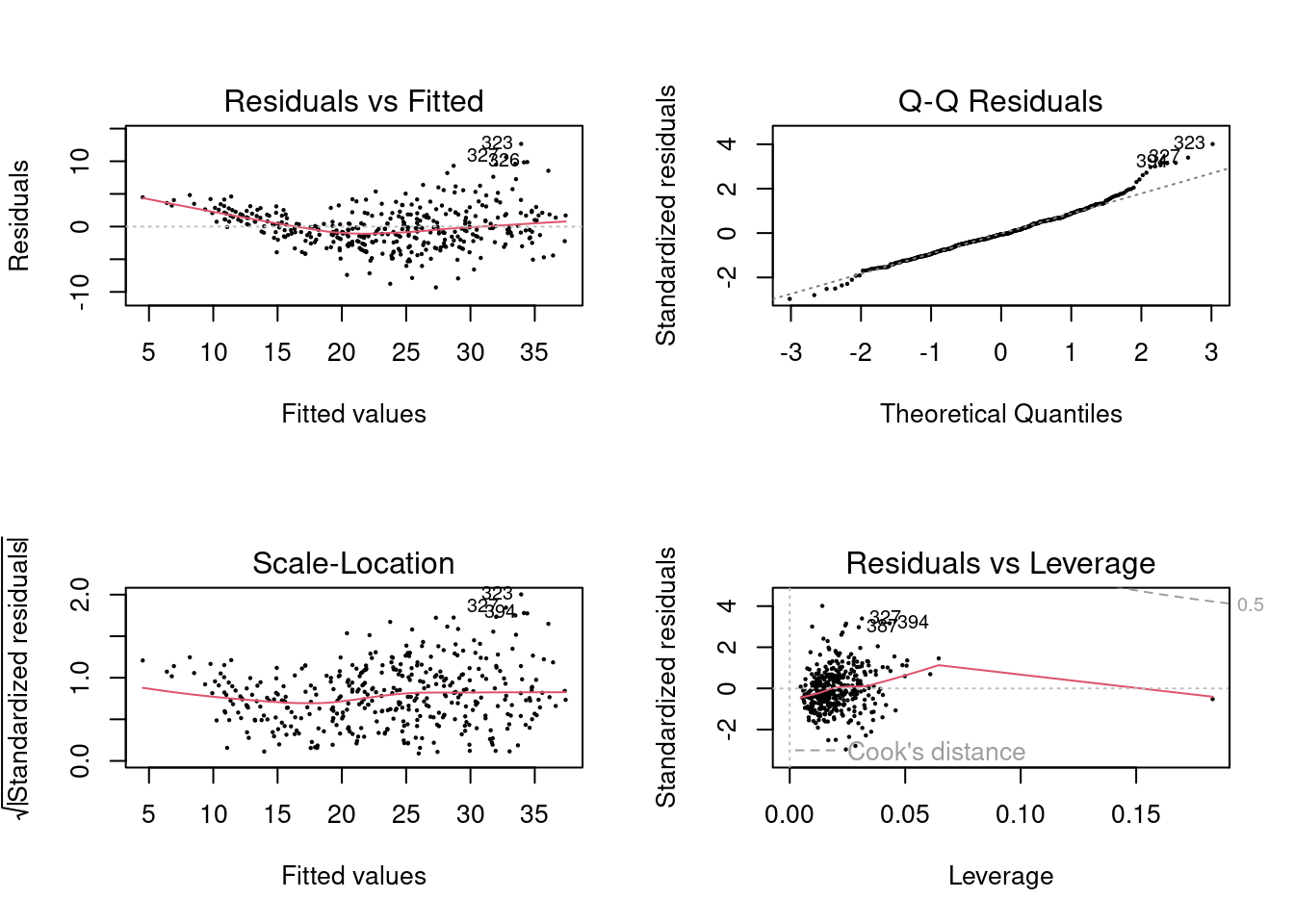
A log transformation of horsepower appears to give a more linear relationship
with mpg.
3.2.3 Question 10
This question should be answered using the
Carseatsdata set.
- Fit a multiple regression model to predict
SalesusingPrice,Urban, andUS.
- Provide an interpretation of each coefficient in the model. Be careful—some of the variables in the model are qualitative!
##
## Call:
## lm(formula = Sales ~ Price + Urban + US, data = Carseats)
##
## Residuals:
## Min 1Q Median 3Q Max
## -6.9206 -1.6220 -0.0564 1.5786 7.0581
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 13.043469 0.651012 20.036 < 2e-16 ***
## Price -0.054459 0.005242 -10.389 < 2e-16 ***
## UrbanYes -0.021916 0.271650 -0.081 0.936
## USYes 1.200573 0.259042 4.635 4.86e-06 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 2.472 on 396 degrees of freedom
## Multiple R-squared: 0.2393, Adjusted R-squared: 0.2335
## F-statistic: 41.52 on 3 and 396 DF, p-value: < 2.2e-16The coefficients are interpreted with the other predictors held fixed:
(Intercept)\(\approx 13.04\): expectedSales(thousands of units) for a non-urban, non-US store withPriceof 0.Price\(\approx -0.054\): each one-dollar increase inPriceis associated with about 54 fewer units sold. Strongly significant.UrbanYes\(\approx -0.022\): urban stores sell about 22 fewer units than non-urban stores. Not significant.USYes\(\approx 1.20\): US stores sell about 1200 more units than non-US stores. Strongly significant.
- Write out the model in equation form, being careful to handle the qualitative variables properly.
\[ \textit{Sales} = 13 + -0.054 \times \textit{Price} + \begin{cases} -0.022, & \text{if $\textit{Urban}$ is Yes, $\textit{US}$ is No} \\ 1.20, & \text{if $\textit{Urban}$ is No, $\textit{US}$ is Yes} \\ 1.18, & \text{if $\textit{Urban}$ and $\textit{US}$ is Yes} \\ 0, & \text{Otherwise} \end{cases} \]
- For which of the predictors can you reject the null hypothesis \(H_0 : \beta_j = 0\)?
Price and US (Urban shows no significant difference between “No” and “Yes”)
- On the basis of your response to the previous question, fit a smaller model that only uses the predictors for which there is evidence of association with the outcome.
- How well do the models in (a) and (e) fit the data?
##
## Call:
## lm(formula = Sales ~ Price + Urban + US, data = Carseats)
##
## Residuals:
## Min 1Q Median 3Q Max
## -6.9206 -1.6220 -0.0564 1.5786 7.0581
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 13.043469 0.651012 20.036 < 2e-16 ***
## Price -0.054459 0.005242 -10.389 < 2e-16 ***
## UrbanYes -0.021916 0.271650 -0.081 0.936
## USYes 1.200573 0.259042 4.635 4.86e-06 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 2.472 on 396 degrees of freedom
## Multiple R-squared: 0.2393, Adjusted R-squared: 0.2335
## F-statistic: 41.52 on 3 and 396 DF, p-value: < 2.2e-16##
## Call:
## lm(formula = Sales ~ Price + US, data = Carseats)
##
## Residuals:
## Min 1Q Median 3Q Max
## -6.9269 -1.6286 -0.0574 1.5766 7.0515
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 13.03079 0.63098 20.652 < 2e-16 ***
## Price -0.05448 0.00523 -10.416 < 2e-16 ***
## USYes 1.19964 0.25846 4.641 4.71e-06 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 2.469 on 397 degrees of freedom
## Multiple R-squared: 0.2393, Adjusted R-squared: 0.2354
## F-statistic: 62.43 on 2 and 397 DF, p-value: < 2.2e-16## Analysis of Variance Table
##
## Model 1: Sales ~ Price + Urban + US
## Model 2: Sales ~ Price + US
## Res.Df RSS Df Sum of Sq F Pr(>F)
## 1 396 2420.8
## 2 397 2420.9 -1 -0.03979 0.0065 0.9357They have similar \(R^2\) and the model containing the extra variable “Urban” is non-significantly better.
- Using the model from (e), obtain 95% confidence intervals for the coefficient(s).
## 2.5 % 97.5 %
## (Intercept) 11.79032020 14.27126531
## Price -0.06475984 -0.04419543
## USYes 0.69151957 1.70776632
- Is there evidence of outliers or high leverage observations in the model from (e)?
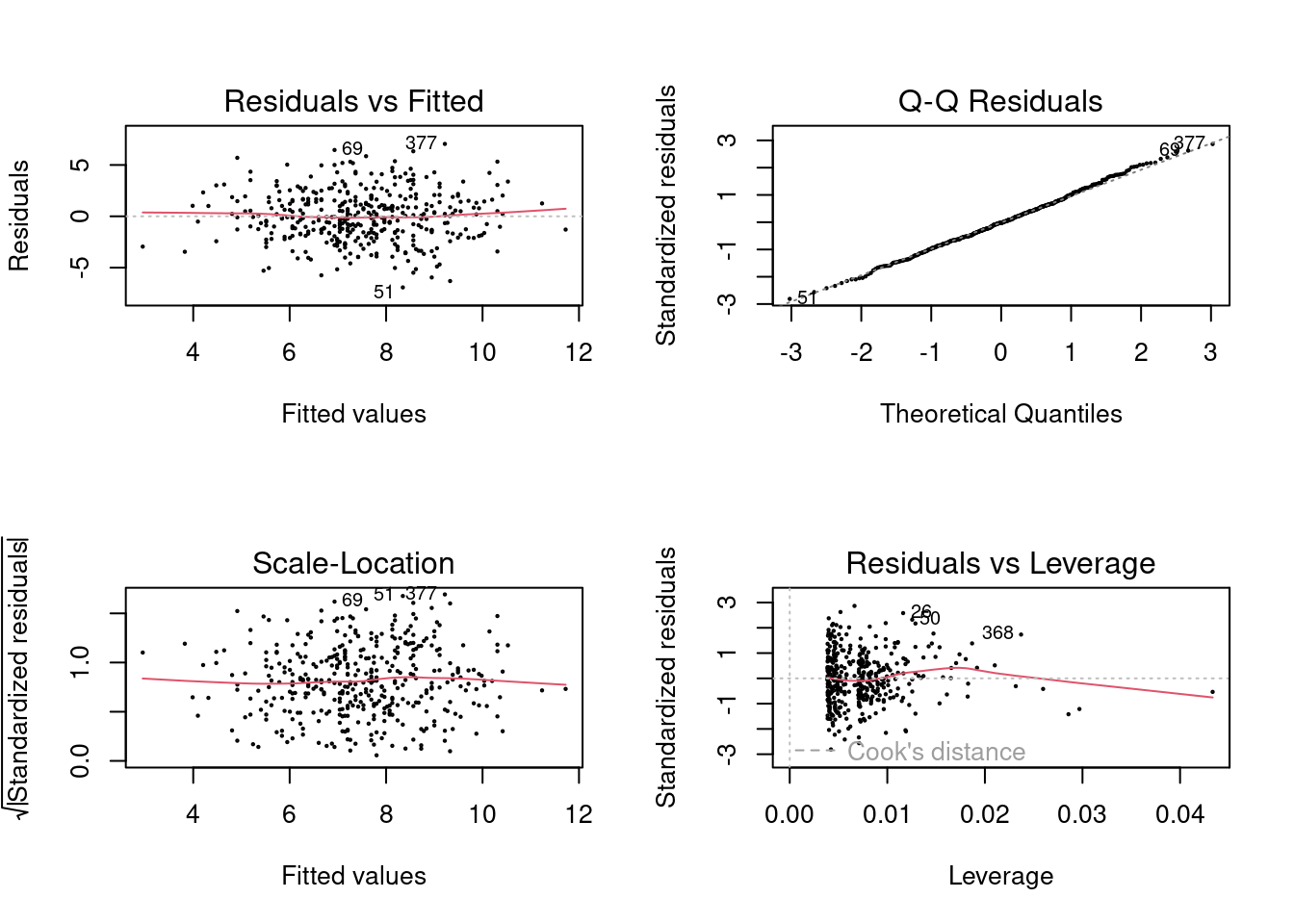
Yes, somewhat.
3.2.4 Question 11
In this problem we will investigate the t-statistic for the null hypothesis \(H_0 : \beta = 0\) in simple linear regression without an intercept. To begin, we generate a predictor
xand a responseyas follows.
- Perform a simple linear regression of
yontox, without an intercept. Report the coefficient estimate \(\hat{\beta}\), the standard error of this coefficient estimate, and the t-statistic and p-value associated with the null hypothesis \(H_0 : \beta = 0\). Comment on these results. (You can perform regression without an intercept using the commandlm(y~x+0).)
## Estimate Std. Error t value Pr(>|t|)
## x 1.993876 0.1064767 18.72593 2.642197e-34There’s a significant positive relationship between \(y\) and \(x\). \(y\) values are predicted to be (a little below) twice the \(x\) values.
- Now perform a simple linear regression of
xontoywithout an intercept, and report the coefficient estimate, its standard error, and the corresponding t-statistic and p-values associated with the null hypothesis \(H_0 : \beta = 0\). Comment on these results.
## Estimate Std. Error t value Pr(>|t|)
## y 0.3911145 0.02088625 18.72593 2.642197e-34There’s a significant positive relationship between \(x\) and \(y\). \(x\) values are predicted to be (a little below) half the \(y\) values.
- What is the relationship between the results obtained in (a) and (b)?
Without error, the coefficients would be the inverse of each other (2 and 1/2). The t-statistic and p-values are the same.
- For the regression of \(Y\) onto \(X\) without an intercept, the t-statistic for \(H_0 : \beta = 0\) takes the form \(\hat{\beta}/SE(\hat{\beta})\), where \(\hat{\beta}\) is given by (3.38), and where \[ SE(\hat\beta) = \sqrt{\frac{\sum_{i=1}^n(y_i - x_i\hat\beta)^2}{(n-1)\sum_{i'=1}^nx_{i'}^2}}. \] (These formulas are slightly different from those given in Sections 3.1.1 and 3.1.2, since here we are performing regression without an intercept.) Show algebraically, and confirm numerically in R, that the t-statistic can be written as \[ \frac{(\sqrt{n-1}) \sum_{i-1}^nx_iy_i)} {\sqrt{(\sum_{i=1}^nx_i^2)(\sum_{i'=1}^ny_{i'}^2)-(\sum_{i'=1}^nx_{i'}y_{i'})^2}} \]
\[ \beta = \sum_i x_i y_i / \sum_{i'} x_{i'}^2 ,\]
therefore
\[\begin{align} t &= \frac{\sum_i x_i y_i \sqrt{n-1} \sqrt{\sum_ix_i^2}} {\sum_i x_i^2 \sqrt{\sum_i(y_i - x_i \beta)^2}} \\ &= \frac{\sum_i x_i y_i \sqrt{n-1}} {\sqrt{\sum_ix_i^2 \sum_i(y_i - x_i \beta)^2}} \\ &= \frac{\sum_i x_i y_i \sqrt{n-1}} {\sqrt{ \sum_ix_i^2 \sum_i(y_i^2 - 2 y_i x_i \beta + x_i^2 \beta^2) }} \\ &= \frac{\sum_i x_i y_i \sqrt{n-1}} {\sqrt{ \sum_ix_i^2 \sum_iy_i^2 - \beta \sum_ix_i^2 (2 \sum_i y_i x_i -\beta \sum_i x_i^2) }} \\ &= \frac{\sum_i x_i y_i \sqrt{n-1}} {\sqrt{ \sum_ix_i^2 \sum_iy_i^2 - \sum_i x_i y_i (2 \sum_i y_i x_i - \sum_i x_i y_i) }} \\ &= \frac{\sum_i x_i y_i \sqrt{n-1}} {\sqrt{\sum_ix_i^2 \sum_iy_i^2 - (\sum_i x_i y_i)^2}} \\ \end{align}\]
We can show this numerically in R by computing \(t\) using the above equation.
## [1] 18.72593
- Using the results from (d), argue that the t-statistic for the regression of y onto x is the same as the t-statistic for the regression of
xontoy.
Swapping \(x_i\) for \(y_i\) in the formula for \(t\) will give the same result.
- In
R, show that when regression is performed with an intercept, the t-statistic for \(H_0 : \beta_1 = 0\) is the same for the regression ofyontoxas it is for the regression ofxontoy.
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -0.03769261 0.09698729 -0.3886346 6.983896e-01
## x 1.99893961 0.10772703 18.5555993 7.723851e-34## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 0.03880394 0.04266144 0.9095787 3.652764e-01
## y 0.38942451 0.02098690 18.5555993 7.723851e-343.2.5 Question 12
This problem involves simple linear regression without an intercept.
- Recall that the coefficient estimate \(\hat{\beta}\) for the linear regression of \(Y\) onto \(X\) without an intercept is given by (3.38). Under what circumstance is the coefficient estimate for the regression of \(X\) onto \(Y\) the same as the coefficient estimate for the regression of \(Y\) onto \(X\)?
\[ \hat\beta = \sum_i x_iy_i / \sum_{i'} x_{i'}^2 \]
The coefficient for the regression of X onto Y swaps the \(x\) and \(y\) variables:
\[ \hat\beta = \sum_i x_iy_i / \sum_{i'} y_{i'}^2 \]
So they are the same when \(\sum_{i} x_{i}^2 = \sum_{i} y_{i}^2\)
- Generate an example in
Rwith \(n = 100\) observations in which the coefficient estimate for the regression of \(X\) onto \(Y\) is different from the coefficient estimate for the regression of \(Y\) onto \(X\).
## [1] 105.9889 429.4924## x y
## 2.0106218 0.4962439
- Generate an example in
Rwith \(n = 100\) observations in which the coefficient estimate for the regression of \(X\) onto \(Y\) is the same as the coefficient estimate for the regression of \(Y\) onto \(X\).
## [1] 135.5844 134.5153## x y
## 0.9925051 1.00067653.2.6 Question 13
In this exercise you will create some simulated data and will fit simple linear regression models to it. Make sure to use
set.seed(1)prior to starting part (a) to ensure consistent results.
- Using the
rnorm()function, create a vector,x, containing 100 observations drawn from a \(N(0, 1)\) distribution. This represents a feature, \(X\).
- Using the
rnorm()function, create a vector,eps, containing 100 observations drawn from a \(N(0, 0.25)\) distribution—a normal distribution with mean zero and variance 0.25.
- Using x and
eps, generate a vector y according to the model \[Y = -1 + 0.5X + \epsilon\] What is the length of the vectory? What are the values of \(\beta_0\) and \(\beta_1\) in this linear model?
## [1] 100\(\beta_0 = -1\) and \(\beta_1 = 0.5\)
- Create a scatterplot displaying the relationship between
xandy. Comment on what you observe.
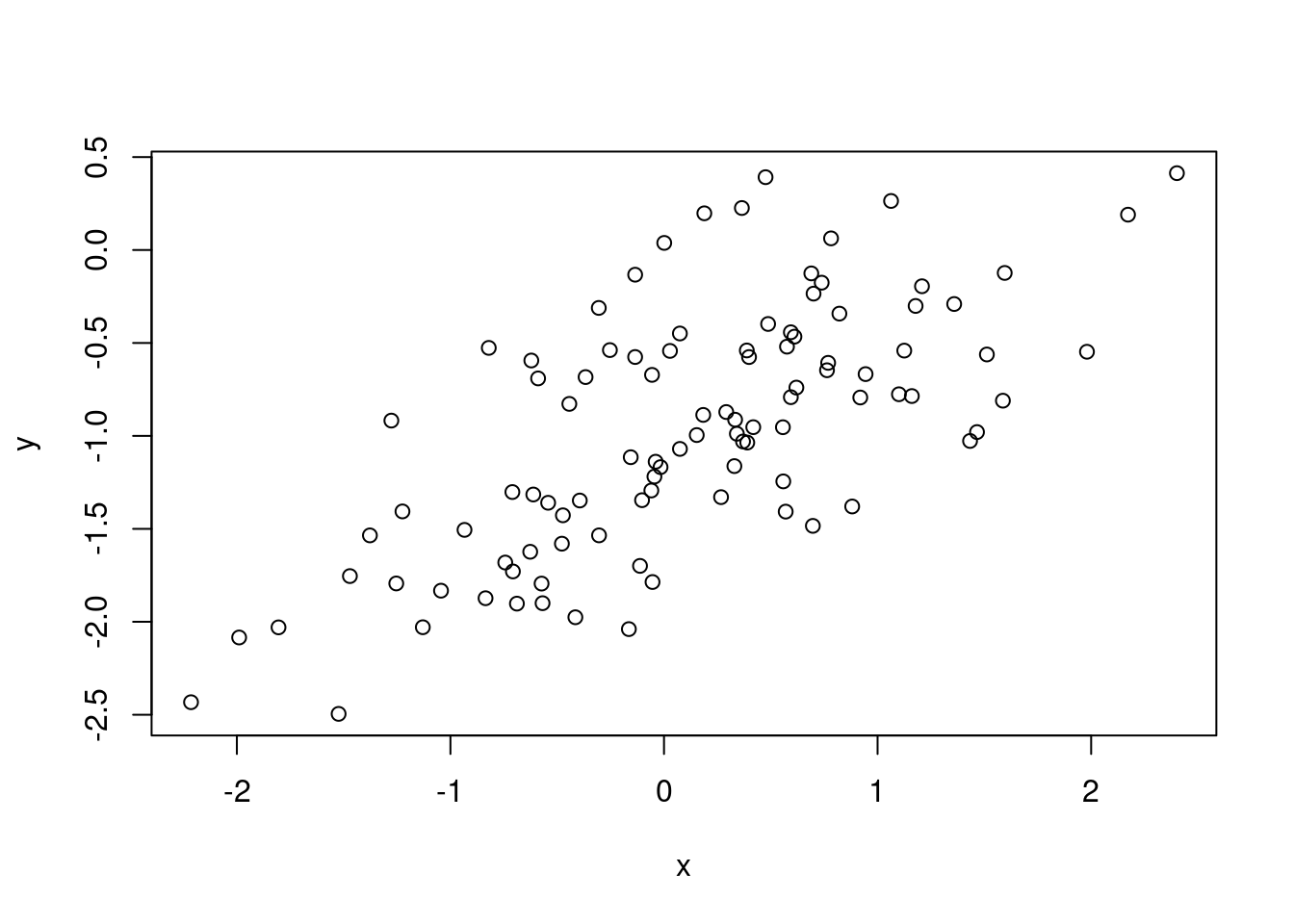
There is a linear relationship between \(x\) and \(y\) (with some error).
- Fit a least squares linear model to predict
yusingx. Comment on the model obtained. How do \(\hat\beta_0\) and \(\hat\beta_1\) compare to \(\beta_0\) and \(\beta_1\)?
##
## Call:
## lm(formula = y ~ x)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.93842 -0.30688 -0.06975 0.26970 1.17309
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -1.01885 0.04849 -21.010 < 2e-16 ***
## x 0.49947 0.05386 9.273 4.58e-15 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.4814 on 98 degrees of freedom
## Multiple R-squared: 0.4674, Adjusted R-squared: 0.4619
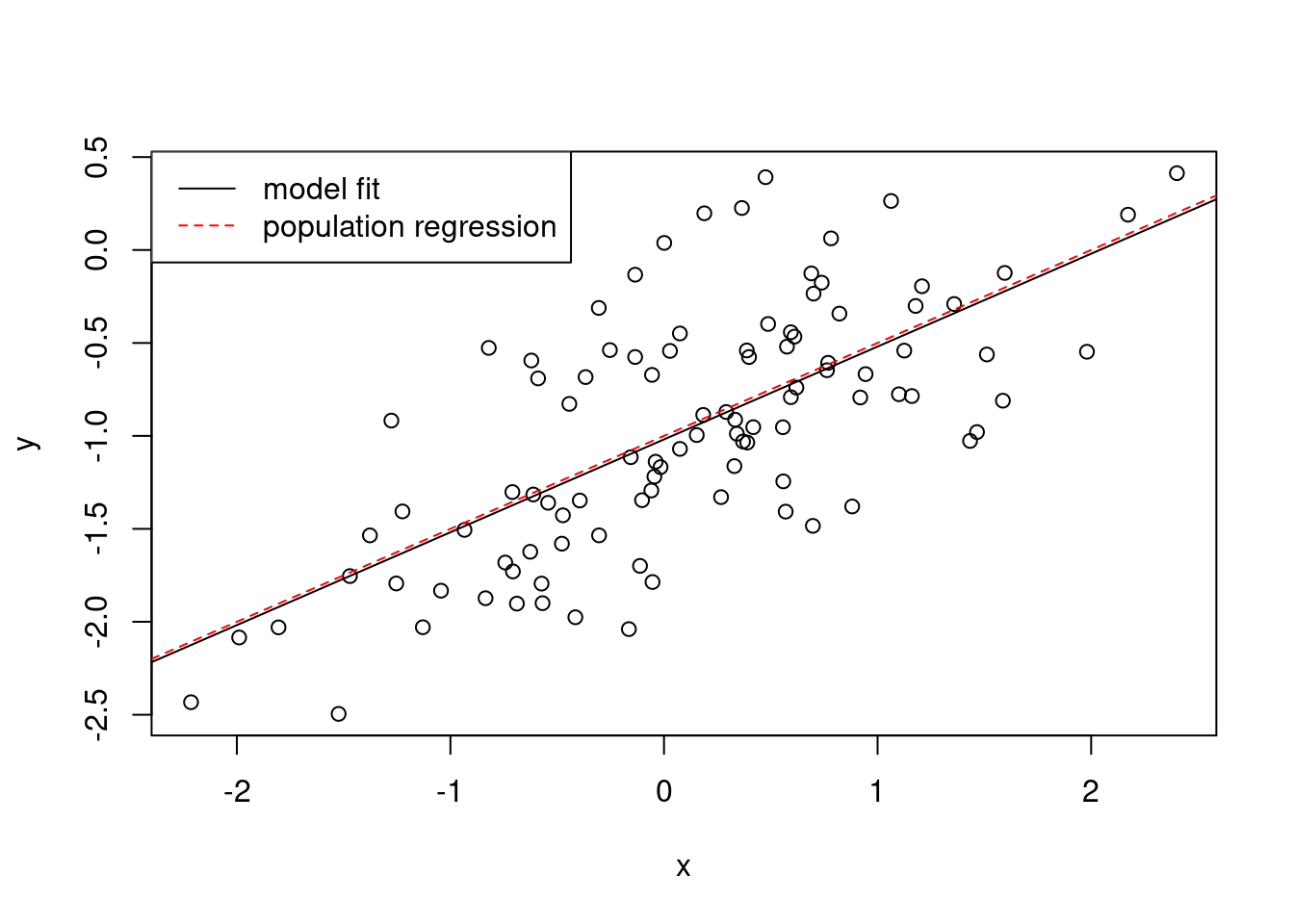
## F-statistic: 85.99 on 1 and 98 DF, p-value: 4.583e-15\(\beta_0\) and \(\beta_1\) are close to their population values.
- Display the least squares line on the scatterplot obtained in (d). Draw the population regression line on the plot, in a different color. Use the
legend()command to create an appropriate legend.
plot(x, y)
abline(fit)
abline(-1, 0.5, col = "red", lty = 2)
legend("topleft",
c("model fit", "population regression"),
col = c("black", "red"),
lty = c(1, 2)
)
- Now fit a polynomial regression model that predicts
yusingxandx^2. Is there evidence that the quadratic term improves the model fit? Explain your answer.
## Analysis of Variance Table
##
## Model 1: y ~ poly(x, 2)
## Model 2: y ~ x
## Res.Df RSS Df Sum of Sq F Pr(>F)
## 1 97 22.257
## 2 98 22.709 -1 -0.45163 1.9682 0.1638There is no evidence for an improved fit, since the F-test is non-significant.
- Repeat (a)–(f) after modifying the data generation process in such a way that there is less noise in the data. The model (3.39) should remain the same. You can do this by decreasing the variance of the normal distribution used to generate the error term \(\epsilon\) in (b). Describe your results.
##
## Call:
## lm(formula = y ~ x)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.61308 -0.12553 -0.00391 0.15199 0.41332
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -0.98917 0.02216 -44.64 <2e-16 ***
## x 0.52375 0.02152 24.33 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.2215 on 98 degrees of freedom
## Multiple R-squared: 0.858, Adjusted R-squared: 0.8565
## F-statistic: 592.1 on 1 and 98 DF, p-value: < 2.2e-16plot(x, y)
abline(fit2)
abline(-1, 0.5, col = "red", lty = 2)
legend("topleft",
c("model fit", "population regression"),
col = c("black", "red"),
lty = c(1, 2)
)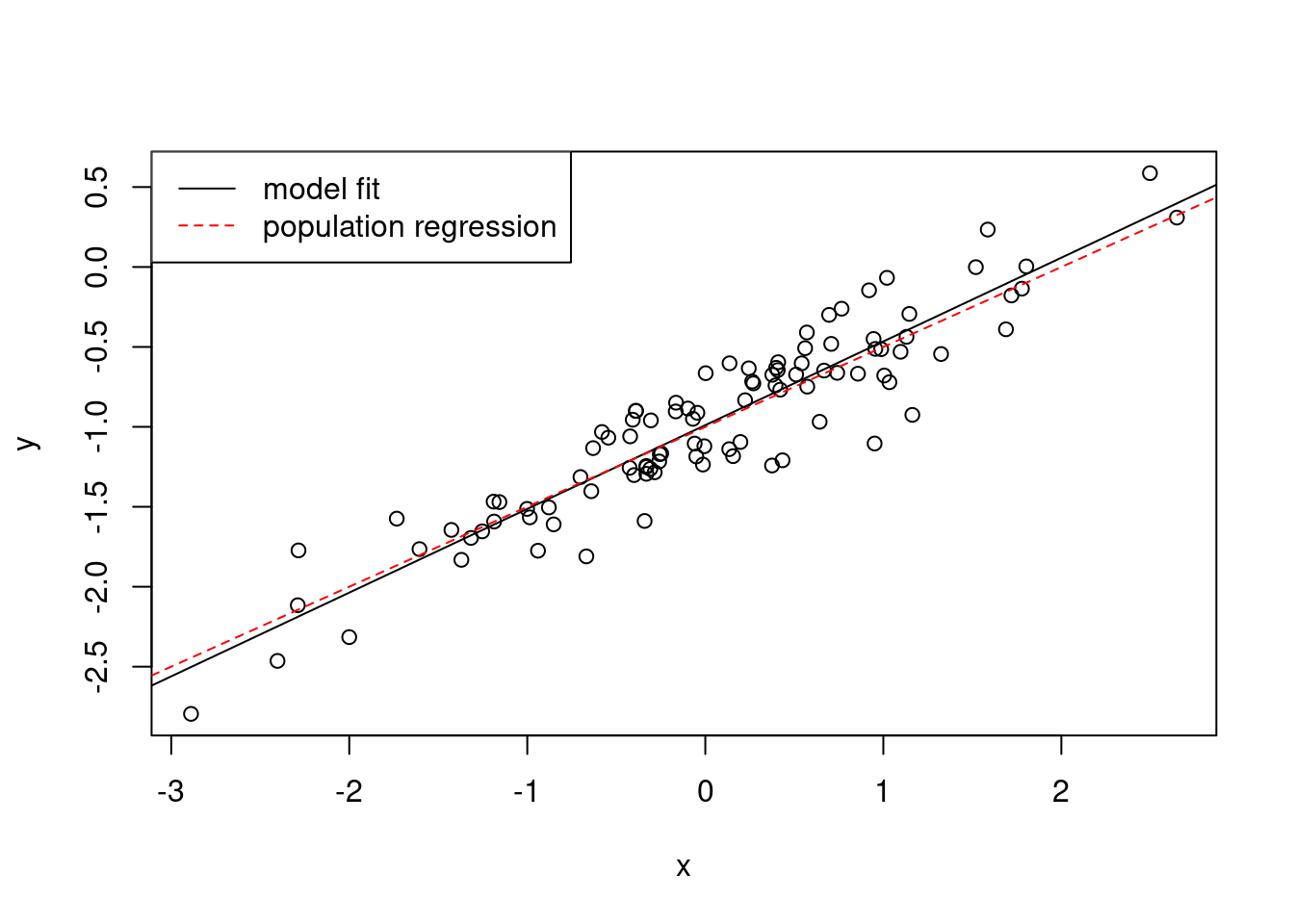
The data shows less variability and the \(R^2\) is higher.
- Repeat (a)–(f) after modifying the data generation process in such a way that there is more noise in the data. The model (3.39) should remain the same. You can do this by increasing the variance of the normal distribution used to generate the error term \(\epsilon\) in (b). Describe your results.
##
## Call:
## lm(formula = y ~ x)
##
## Residuals:
## Min 1Q Median 3Q Max
## -2.51014 -0.60549 0.02065 0.70483 2.08980
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -1.04745 0.09676 -10.825 < 2e-16 ***
## x 0.42505 0.08310 5.115 1.56e-06 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.9671 on 98 degrees of freedom
## Multiple R-squared: 0.2107, Adjusted R-squared: 0.2027
## F-statistic: 26.16 on 1 and 98 DF, p-value: 1.56e-06plot(x, y)
abline(fit3)
abline(-1, 0.5, col = "red", lty = 2)
legend("topleft",
c("model fit", "population regression"),
col = c("black", "red"),
lty = c(1, 2)
)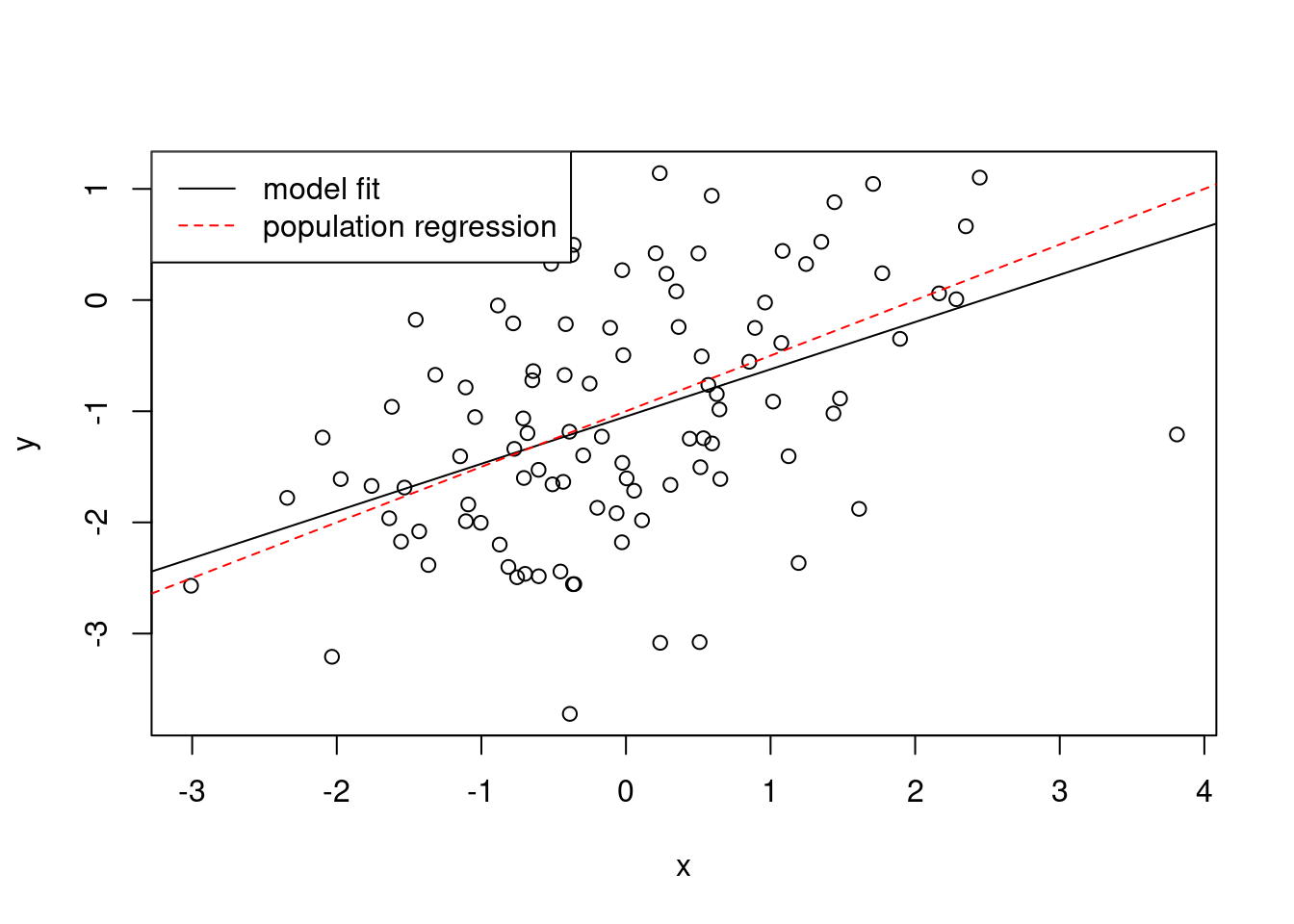
The data shows more variability. The \(R^2\) is lower.
- What are the confidence intervals for \(\beta_0\) and \(\beta_1\) based on the original data set, the noisier data set, and the less noisy data set? Comment on your results.
## 2.5 % 97.5 %
## (Intercept) -1.1150804 -0.9226122
## x 0.3925794 0.6063602## 2.5 % 97.5 %
## (Intercept) -1.033141 -0.9451916
## x 0.481037 0.5664653## 2.5 % 97.5 %
## (Intercept) -1.2394772 -0.8554276
## x 0.2601391 0.5899632The confidence intervals for the coefficients are smaller when there is less error.
3.2.7 Question 14
This problem focuses on the collinearity problem.
Perform the following commands in R :
> set.seed(1) > x1 <- runif(100) > x2 <- 0.5 * x1 + rnorm(100) / 10 > y <- 2 + 2 * x1 + 0.3 * x2 + rnorm(100)The last line corresponds to creating a linear model in which
yis a function ofx1andx2. Write out the form of the linear model. What are the regression coefficients?
set.seed(1)
x1 <- runif(100)
x2 <- 0.5 * x1 + rnorm(100) / 10
y <- 2 + 2 * x1 + 0.3 * x2 + rnorm(100)The model is of the form:
\[Y = \beta_0 + \beta_1X_1 + \beta_2X_2 + \epsilon\]
The coefficients are \(\beta_0 = 2\), \(\beta_1 = 2\), \(\beta_2 = 0.3\).
- What is the correlation between
x1andx2? Create a scatterplot displaying the relationship between the variables.
## [1] 0.8351212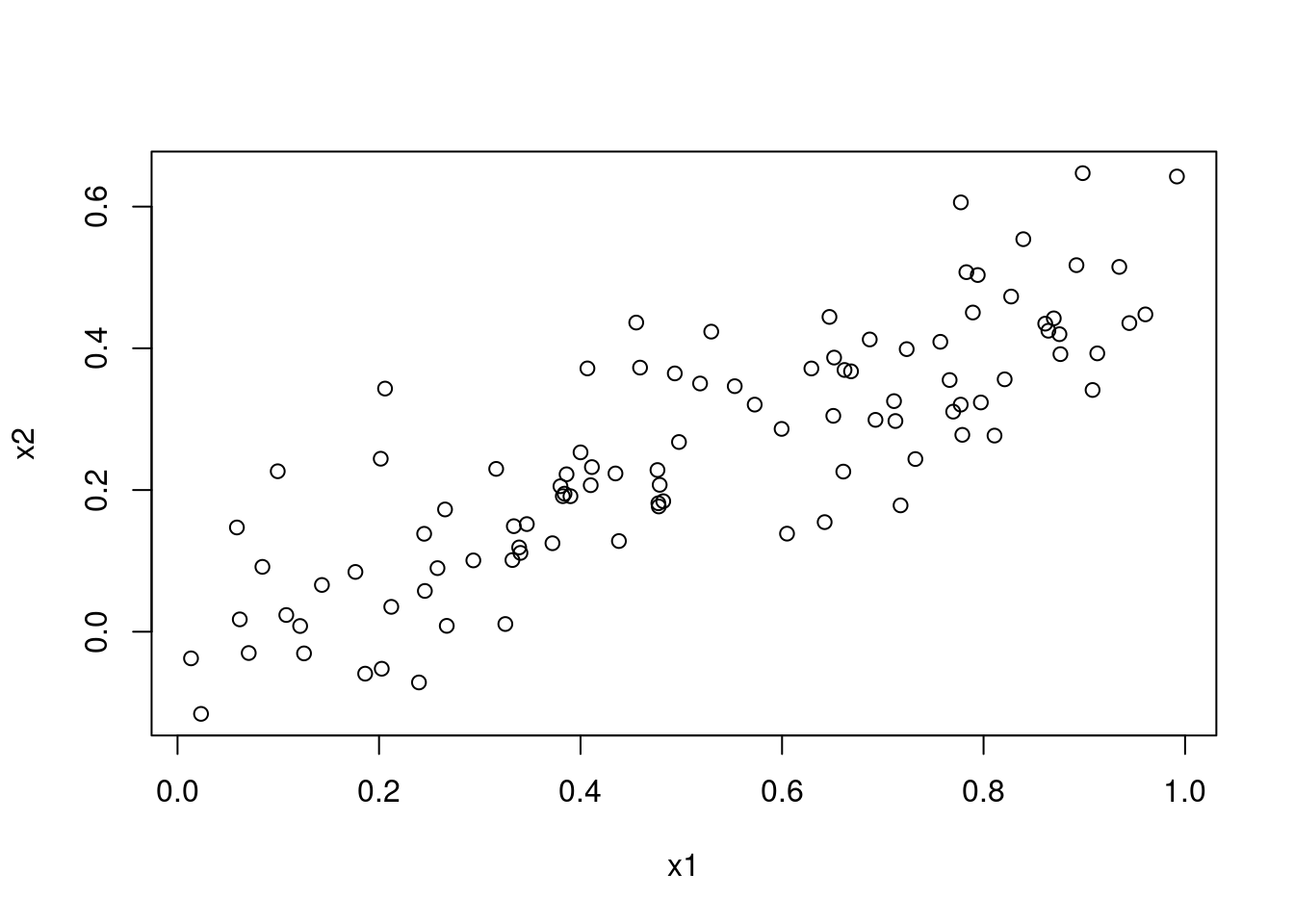
- Using this data, fit a least squares regression to predict
yusingx1andx2. Describe the results obtained. What are \(\hat\beta_0\), \(\hat\beta_1\), and \(\hat\beta_2\)? How do these relate to the true \(\beta_0\), \(\beta_1\), and _2$? Can you reject the null hypothesis \(H_0 : \beta_1\) = 0$? How about the null hypothesis \(H_0 : \beta_2 = 0\)?
##
## Call:
## lm(formula = y ~ x1 + x2)
##
## Residuals:
## Min 1Q Median 3Q Max
## -2.8311 -0.7273 -0.0537 0.6338 2.3359
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 2.1305 0.2319 9.188 7.61e-15 ***
## x1 1.4396 0.7212 1.996 0.0487 *
## x2 1.0097 1.1337 0.891 0.3754
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.056 on 97 degrees of freedom
## Multiple R-squared: 0.2088, Adjusted R-squared: 0.1925
## F-statistic: 12.8 on 2 and 97 DF, p-value: 1.164e-05\(\hat\beta_0 = 2.13\), \(\hat\beta_1 = 1.43\), and \(\hat\beta_2 = 1.01\). These are relatively poor estimates of the true values. We can reject the hypothesis that \(H_0 : \beta_1\) at a p-value of 0.05 (just about). We cannot reject the hypothesis that \(H_0 : \beta_2 = 0\).
- Now fit a least squares regression to predict
yusing onlyx1. Comment on your results. Can you reject the null hypothesis \(H 0 : \beta_1 = 0\)?
##
## Call:
## lm(formula = y ~ x1)
##
## Residuals:
## Min 1Q Median 3Q Max
## -2.89495 -0.66874 -0.07785 0.59221 2.45560
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 2.1124 0.2307 9.155 8.27e-15 ***
## x1 1.9759 0.3963 4.986 2.66e-06 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.055 on 98 degrees of freedom
## Multiple R-squared: 0.2024, Adjusted R-squared: 0.1942
## F-statistic: 24.86 on 1 and 98 DF, p-value: 2.661e-06We can reject \(H_0 : \beta_1 = 0\). The p-value is much more significant for
\(\beta_1\) compared to when x2 is included in the model.
- Now fit a least squares regression to predict
yusing onlyx2. Comment on your results. Can you reject the null hypothesis \(H_0 : \beta_1 = 0\)?
##
## Call:
## lm(formula = y ~ x2)
##
## Residuals:
## Min 1Q Median 3Q Max
## -2.62687 -0.75156 -0.03598 0.72383 2.44890
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 2.3899 0.1949 12.26 < 2e-16 ***
## x2 2.8996 0.6330 4.58 1.37e-05 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.072 on 98 degrees of freedom
## Multiple R-squared: 0.1763, Adjusted R-squared: 0.1679
## F-statistic: 20.98 on 1 and 98 DF, p-value: 1.366e-05Similarly, we can reject \(H_0 : \beta_2 = 0\). The p-value is much more
significant for \(\beta_2\) compared to when x1 is included in the model.
- Do the results obtained in (c)–(e) contradict each other? Explain your answer.
No they do not contradict each other. Both x1 and x2 individually are
capable of explaining much of the variation observed in y, however since they
are correlated, it is very difficult to tease apart their separate
contributions.
Now suppose we obtain one additional observation, which was unfortunately mismeasured.
Re-fit the linear models from (c) to (e) using this new data. What effect does this new observation have on the each of the models? In each model, is this observation an outlier? A high-leverage point? Both? Explain your answers.
##
## Call:
## lm(formula = y ~ x1 + x2)
##
## Residuals:
## Min 1Q Median 3Q Max
## -2.73348 -0.69318 -0.05263 0.66385 2.30619
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 2.2267 0.2314 9.624 7.91e-16 ***
## x1 0.5394 0.5922 0.911 0.36458
## x2 2.5146 0.8977 2.801 0.00614 **
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.075 on 98 degrees of freedom
## Multiple R-squared: 0.2188, Adjusted R-squared: 0.2029
## F-statistic: 13.72 on 2 and 98 DF, p-value: 5.564e-06##
## Call:
## lm(formula = y ~ x1)
##
## Residuals:
## Min 1Q Median 3Q Max
## -2.8897 -0.6556 -0.0909 0.5682 3.5665
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 2.2569 0.2390 9.445 1.78e-15 ***
## x1 1.7657 0.4124 4.282 4.29e-05 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.111 on 99 degrees of freedom
## Multiple R-squared: 0.1562, Adjusted R-squared: 0.1477
## F-statistic: 18.33 on 1 and 99 DF, p-value: 4.295e-05##
## Call:
## lm(formula = y ~ x2)
##
## Residuals:
## Min 1Q Median 3Q Max
## -2.64729 -0.71021 -0.06899 0.72699 2.38074
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 2.3451 0.1912 12.264 < 2e-16 ***
## x2 3.1190 0.6040 5.164 1.25e-06 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.074 on 99 degrees of freedom
## Multiple R-squared: 0.2122, Adjusted R-squared: 0.2042
## F-statistic: 26.66 on 1 and 99 DF, p-value: 1.253e-06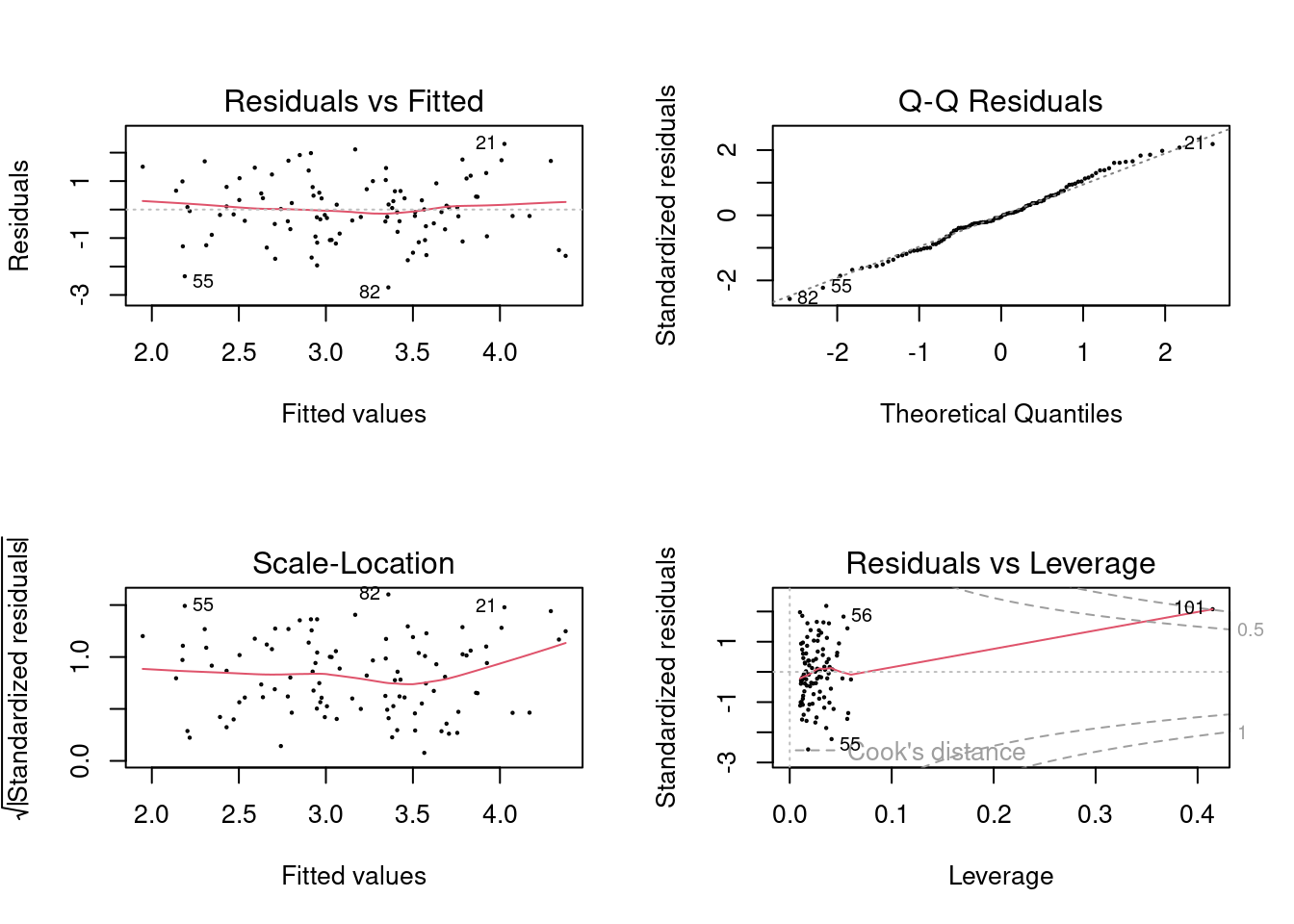
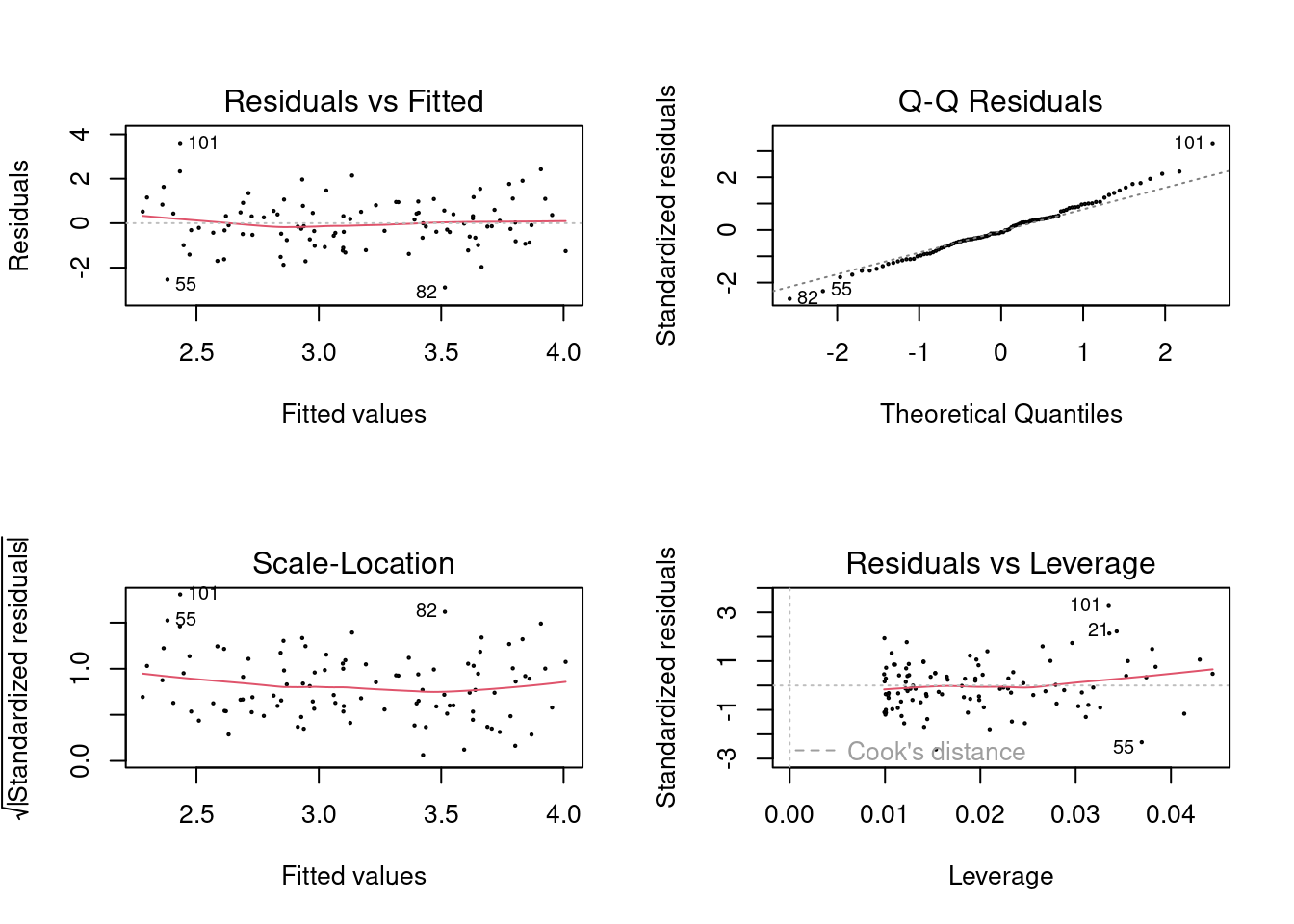
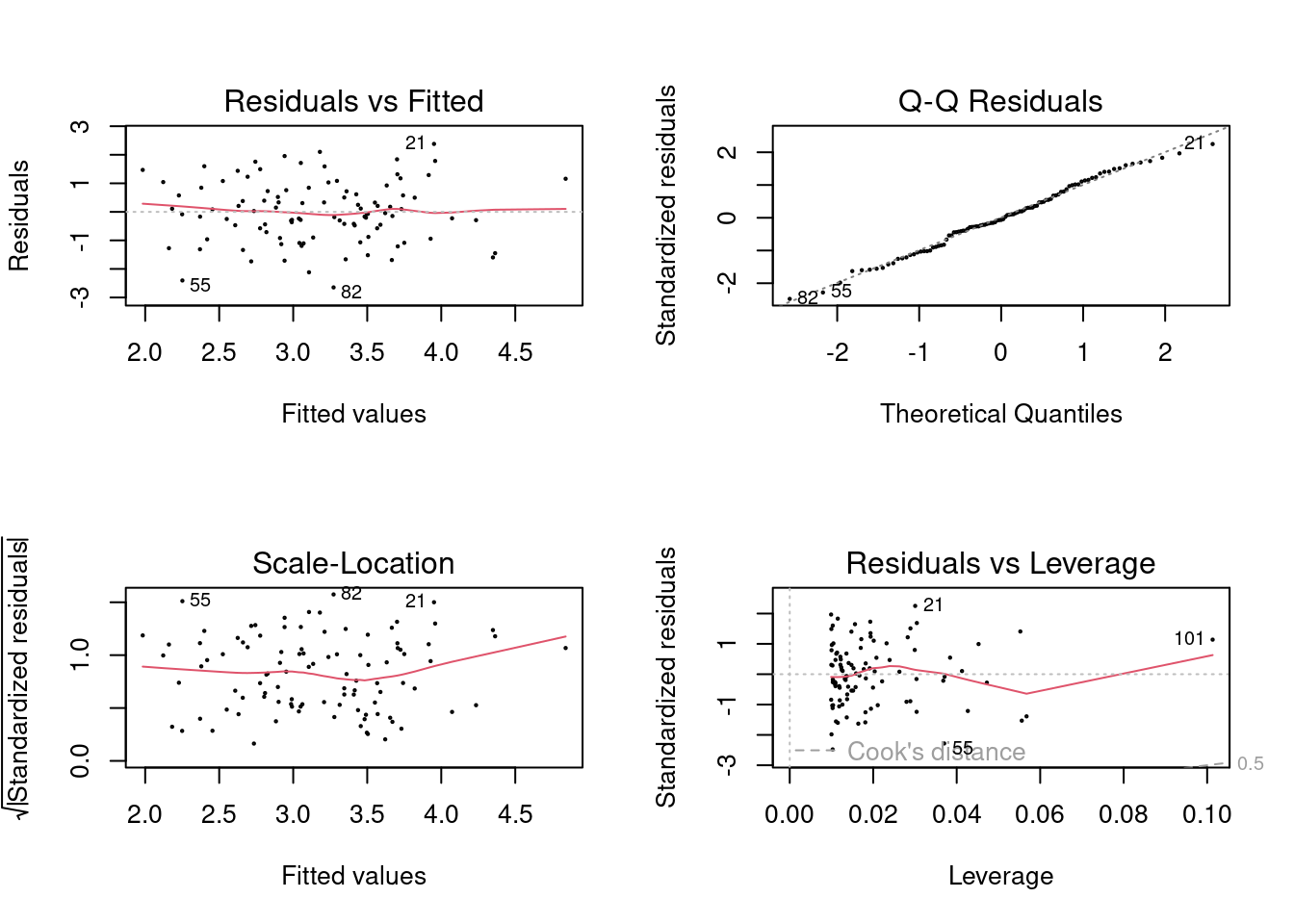
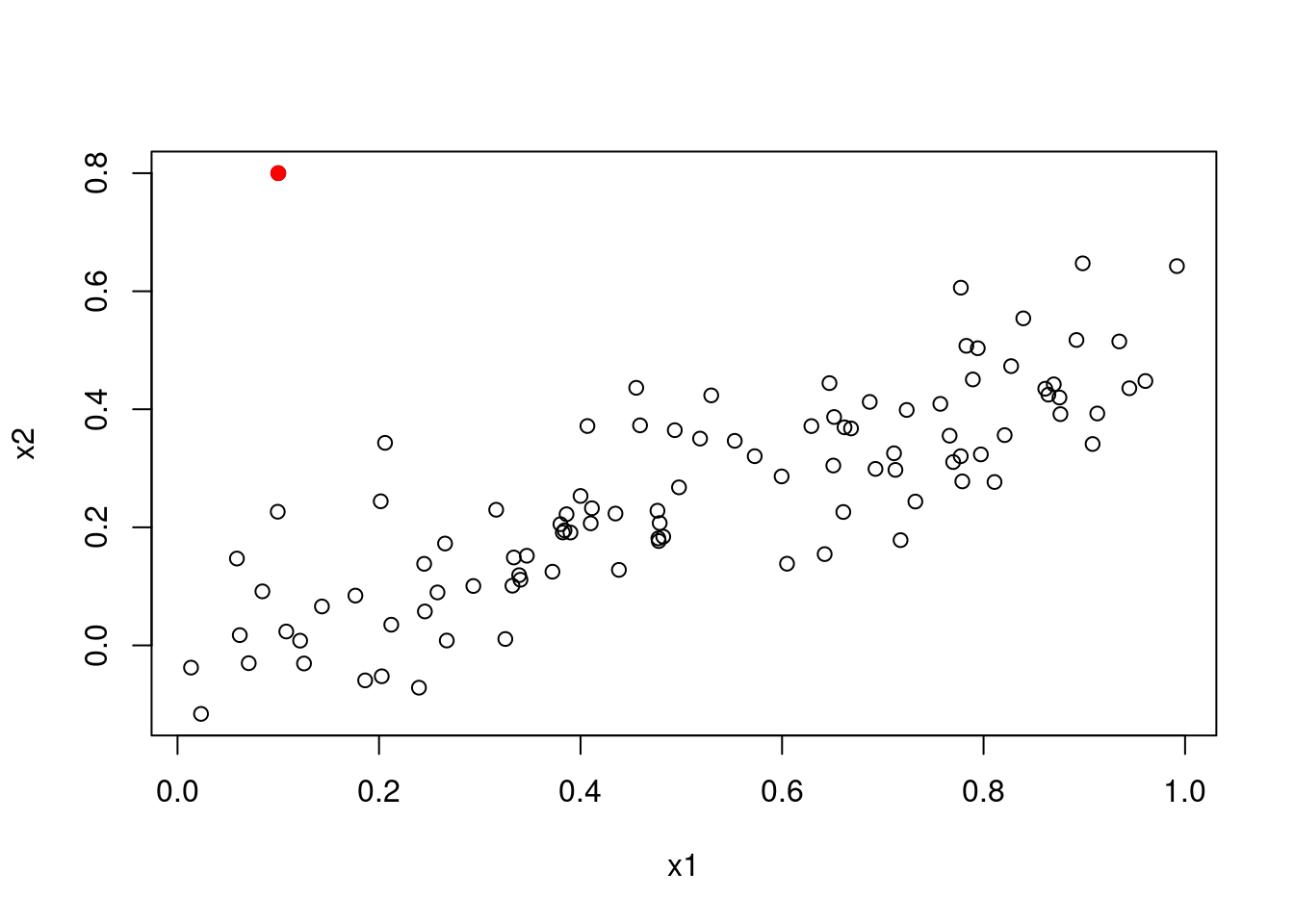
In the first model (with both predictors), the new point has very high leverage
(since it is an outlier in terms of the joint x1 and x2 distribution),
however it is not an outlier. In the model that includes x1, it is an outlier
but does not have high leverage. In the model that includes x2, it has high
leverage but is not an outlier. It is useful to consider the scatterplot of
x1 and x2.
3.2.8 Question 15
This problem involves the
Bostondata set, which we saw in the lab for this chapter. We will now try to predict per capita crime rate using the other variables in this data set. In other words, per capita crime rate is the response, and the other variables are the predictors.
We are trying to predict crim.
- For each predictor, fit a simple linear regression model to predict the response. Describe your results. In which of the models is there a statistically significant association between the predictor and the response? Create some plots to back up your assertions.
fits <- lapply(pred, function(x) lm(Boston$crim ~ x))
printCoefmat(do.call(rbind, lapply(fits, function(x) coef(summary(x))[2, ])))## Estimate Std. Error t value Pr(>|t|)
## zn -0.0739350 0.0160946 -4.5938 5.506e-06 ***
## indus 0.5097763 0.0510243 9.9908 < 2.2e-16 ***
## chas -1.8927766 1.5061155 -1.2567 0.2094
## nox 31.2485312 2.9991904 10.4190 < 2.2e-16 ***
## rm -2.6840512 0.5320411 -5.0448 6.347e-07 ***
## age 0.1077862 0.0127364 8.4628 2.855e-16 ***
## dis -1.5509017 0.1683300 -9.2135 < 2.2e-16 ***
## rad 0.6179109 0.0343318 17.9982 < 2.2e-16 ***
## tax 0.0297423 0.0018474 16.0994 < 2.2e-16 ***
## ptratio 1.1519828 0.1693736 6.8014 2.943e-11 ***
## lstat 0.5488048 0.0477610 11.4907 < 2.2e-16 ***
## medv -0.3631599 0.0383902 -9.4597 < 2.2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1There are significant associations for all predictors with the exception of
chas when fitting separate linear models. For example, consider the following
plot representing the fifth model
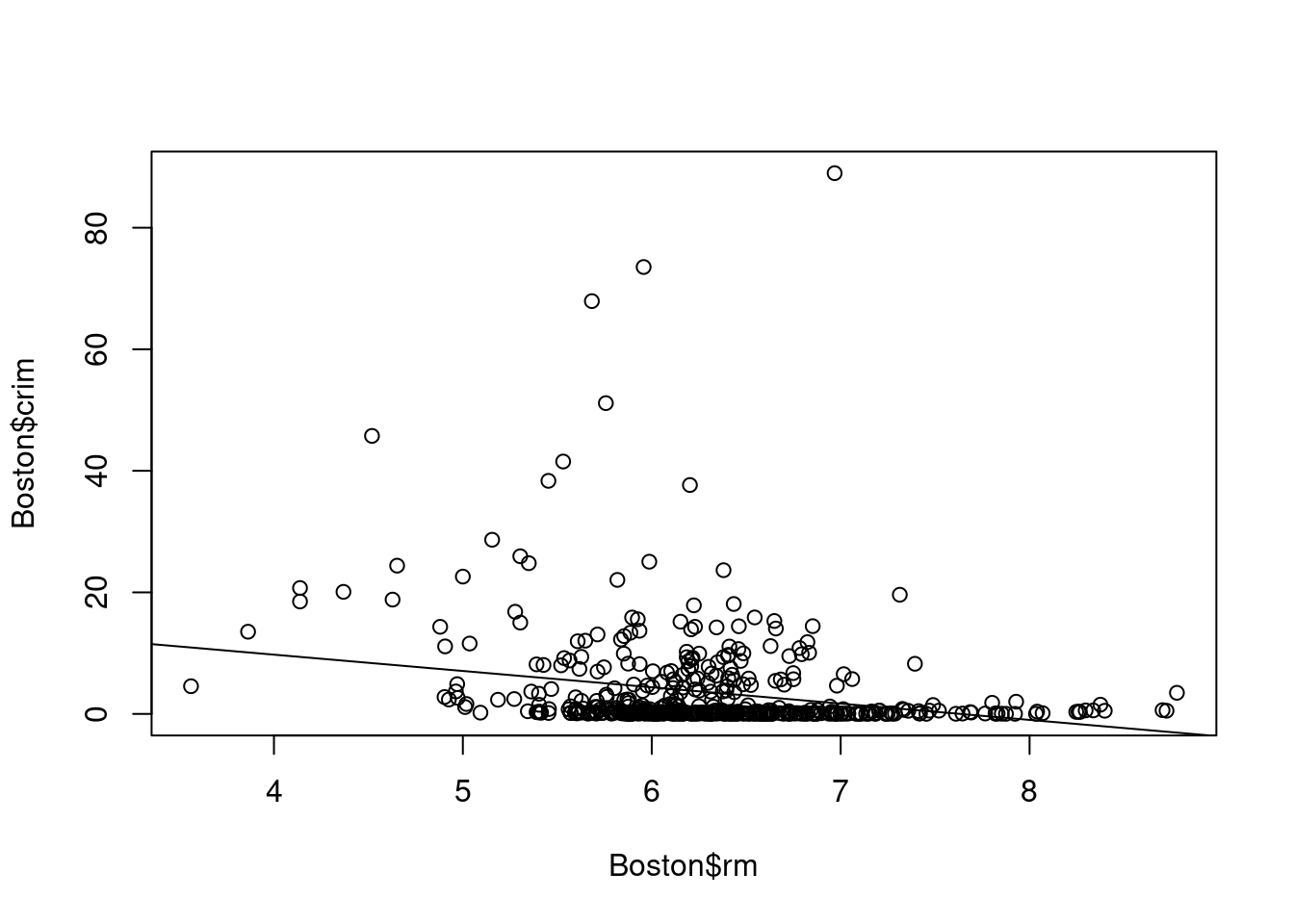
- Fit a multiple regression model to predict the response using all of the predictors. Describe your results. For which predictors can we reject the null hypothesis \(H_0 : \beta_j = 0\)?
##
## Call:
## lm(formula = crim ~ ., data = Boston)
##
## Residuals:
## Min 1Q Median 3Q Max
## -8.534 -2.248 -0.348 1.087 73.923
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 13.7783938 7.0818258 1.946 0.052271 .
## zn 0.0457100 0.0187903 2.433 0.015344 *
## indus -0.0583501 0.0836351 -0.698 0.485709
## chas -0.8253776 1.1833963 -0.697 0.485841
## nox -9.9575865 5.2898242 -1.882 0.060370 .
## rm 0.6289107 0.6070924 1.036 0.300738
## age -0.0008483 0.0179482 -0.047 0.962323
## dis -1.0122467 0.2824676 -3.584 0.000373 ***
## rad 0.6124653 0.0875358 6.997 8.59e-12 ***
## tax -0.0037756 0.0051723 -0.730 0.465757
## ptratio -0.3040728 0.1863598 -1.632 0.103393
## lstat 0.1388006 0.0757213 1.833 0.067398 .
## medv -0.2200564 0.0598240 -3.678 0.000261 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 6.46 on 493 degrees of freedom
## Multiple R-squared: 0.4493, Adjusted R-squared: 0.4359
## F-statistic: 33.52 on 12 and 493 DF, p-value: < 2.2e-16There are now only significant associations for zn, dis, rad, black and
medv.
- How do your results from (a) compare to your results from (b)? Create a plot displaying the univariate regression coefficients from (a) on the \(x\)-axis, and the multiple regression coefficients from (b) on the \(y\)-axis. That is, each predictor is displayed as a single point in the plot. Its coefficient in a simple linear regression model is shown on the x-axis, and its coefficient estimate in the multiple linear regression model is shown on the y-axis.
The results from (b) show reduced significance compared to the models fit in (a).
plot(sapply(fits, function(x) coef(x)[2]), coef(mfit)[-1],
xlab = "Univariate regression",
ylab = "multiple regression"
)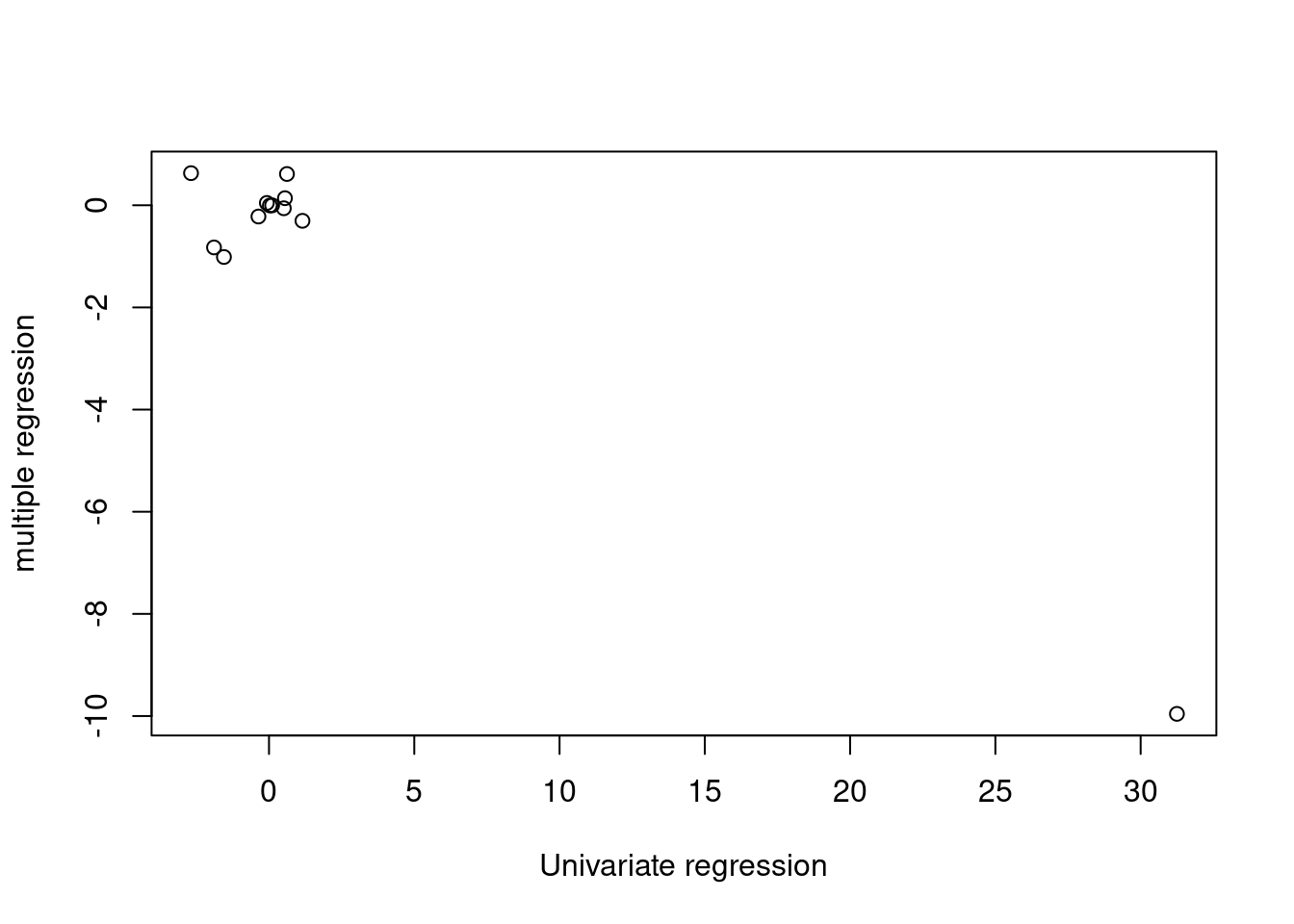
The estimated coefficients differ (in particular the estimated coefficient for
nox is dramatically different) between the two modeling strategies.
- Is there evidence of non-linear association between any of the predictors and the response? To answer this question, for each predictor X, fit a model of the form \[ Y = \beta_0 + \beta_1X + \beta_2X^2 + \beta_3X^3 + \epsilon \]
pred <- subset(pred, select = -chas)
fits <- lapply(names(pred), function(p) {
f <- paste0("crim ~ poly(", p, ", 3)")
lm(as.formula(f), data = Boston)
})
for (fit in fits) printCoefmat(coef(summary(fit)))## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 3.61352 0.37219 9.7088 < 2.2e-16 ***
## poly(zn, 3)1 -38.74984 8.37221 -4.6284 4.698e-06 ***
## poly(zn, 3)2 23.93983 8.37221 2.8594 0.004421 **
## poly(zn, 3)3 -10.07187 8.37221 -1.2030 0.229539
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 3.6135 0.3300 10.9501 < 2.2e-16 ***
## poly(indus, 3)1 78.5908 7.4231 10.5873 < 2.2e-16 ***
## poly(indus, 3)2 -24.3948 7.4231 -3.2863 0.001086 **
## poly(indus, 3)3 -54.1298 7.4231 -7.2920 1.196e-12 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 3.61352 0.32157 11.2370 < 2.2e-16 ***
## poly(nox, 3)1 81.37202 7.23361 11.2492 < 2.2e-16 ***
## poly(nox, 3)2 -28.82859 7.23361 -3.9854 7.737e-05 ***
## poly(nox, 3)3 -60.36189 7.23361 -8.3446 6.961e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 3.6135 0.3703 9.7584 < 2.2e-16 ***
## poly(rm, 3)1 -42.3794 8.3297 -5.0878 5.128e-07 ***
## poly(rm, 3)2 26.5768 8.3297 3.1906 0.001509 **
## poly(rm, 3)3 -5.5103 8.3297 -0.6615 0.508575
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 3.61352 0.34852 10.3683 < 2.2e-16 ***
## poly(age, 3)1 68.18201 7.83970 8.6970 < 2.2e-16 ***
## poly(age, 3)2 37.48447 7.83970 4.7814 2.291e-06 ***
## poly(age, 3)3 21.35321 7.83970 2.7237 0.00668 **
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 3.61352 0.32592 11.0870 < 2.2e-16 ***
## poly(dis, 3)1 -73.38859 7.33148 -10.0101 < 2.2e-16 ***
## poly(dis, 3)2 56.37304 7.33148 7.6892 7.870e-14 ***
## poly(dis, 3)3 -42.62188 7.33148 -5.8135 1.089e-08 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 3.61352 0.29707 12.1639 < 2.2e-16 ***
## poly(rad, 3)1 120.90745 6.68240 18.0934 < 2.2e-16 ***
## poly(rad, 3)2 17.49230 6.68240 2.6177 0.009121 **
## poly(rad, 3)3 4.69846 6.68240 0.7031 0.482314
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 3.61352 0.30468 11.8599 < 2.2e-16 ***
## poly(tax, 3)1 112.64583 6.85371 16.4358 < 2.2e-16 ***
## poly(tax, 3)2 32.08725 6.85371 4.6817 3.665e-06 ***
## poly(tax, 3)3 -7.99681 6.85371 -1.1668 0.2439
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 3.61352 0.36105 10.0084 < 2.2e-16 ***
## poly(ptratio, 3)1 56.04523 8.12158 6.9008 1.565e-11 ***
## poly(ptratio, 3)2 24.77482 8.12158 3.0505 0.002405 **
## poly(ptratio, 3)3 -22.27974 8.12158 -2.7433 0.006301 **
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 3.61352 0.33917 10.6540 <2e-16 ***
## poly(lstat, 3)1 88.06967 7.62944 11.5434 <2e-16 ***
## poly(lstat, 3)2 15.88816 7.62944 2.0825 0.0378 *
## poly(lstat, 3)3 -11.57402 7.62944 -1.5170 0.1299
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 3.61352 0.29203 12.374 < 2.2e-16 ***
## poly(medv, 3)1 -75.05761 6.56915 -11.426 < 2.2e-16 ***
## poly(medv, 3)2 88.08621 6.56915 13.409 < 2.2e-16 ***
## poly(medv, 3)3 -48.03343 6.56915 -7.312 1.047e-12 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Yes there is strong evidence for many variables having non-linear associations.
In many cases, the addition of a cubic term is significant (indus, nox,
age, dis, ptratio and medv). In other cases although the cubic terms
is not significant, the squared term is (zn, rm, rad, tax, lstat).
In only one case, black is there no evidence for a non-linear relationship.